日志过大,引起磁盘空间不足
问题回顾:调度任务执行报错, GreenplumPooledSQLException:.........No space left on device (seg0 172.16.252.39:40000 pid=xxxxx).
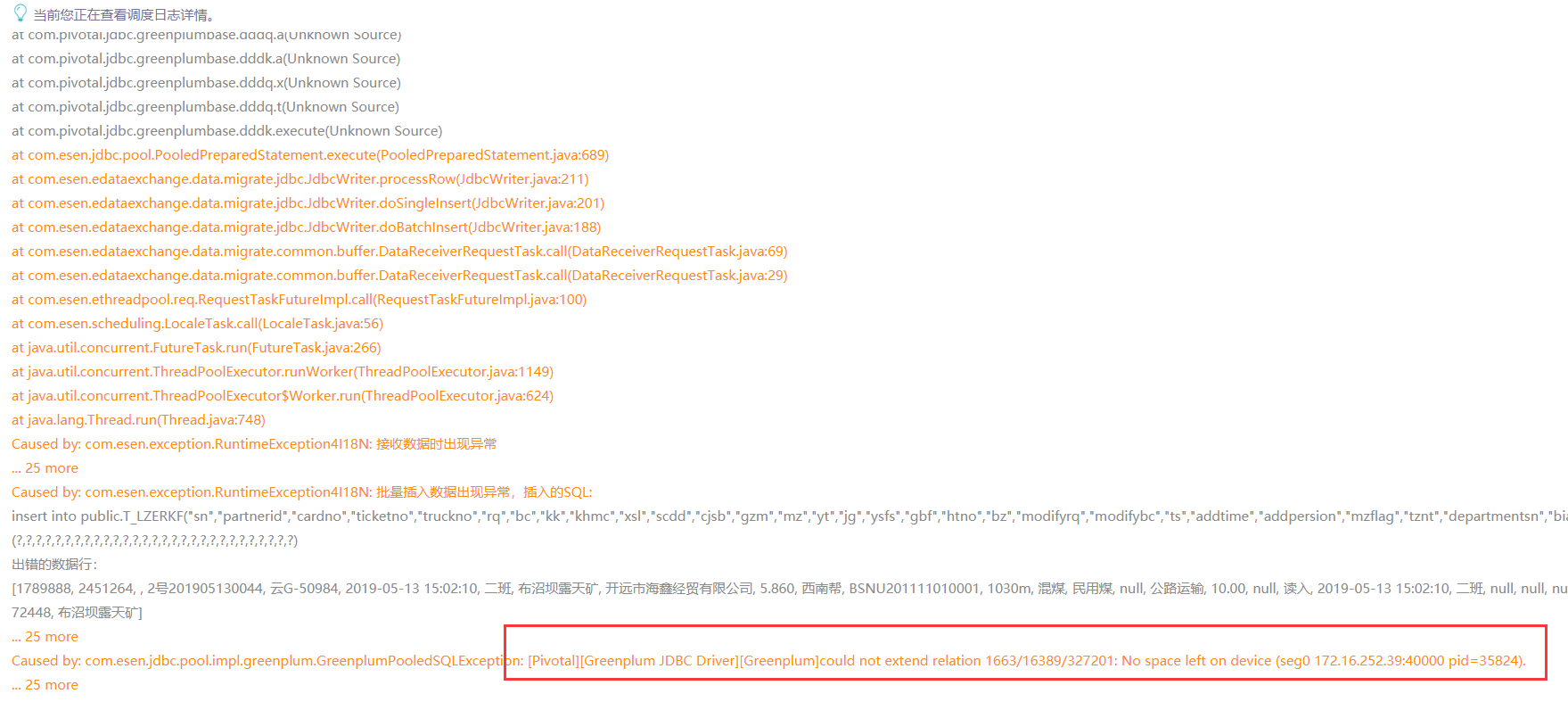
登录服务器,查看磁盘情况,发现占用率已经高达100%:
1 | [root@tdh39 ~]# df -h |
切换到根目录后,执行 du -sh,发现data目录占用高达581G:1
2
3
4
5
6
7
8
9
10[root@tdh39 ~]# cd /
[root@tdh39 /]# du -sh *
0 bin
137M boot
581G data
0 dev
37M etc
143M hadoop
3.8G home
.......
进一步跟踪目录占用后,发现目录为gp510/gpdata,而gpdata是greenplum存放数据的目录。再进入到pg_log,发现存放了大量的csv格式的日志文件:
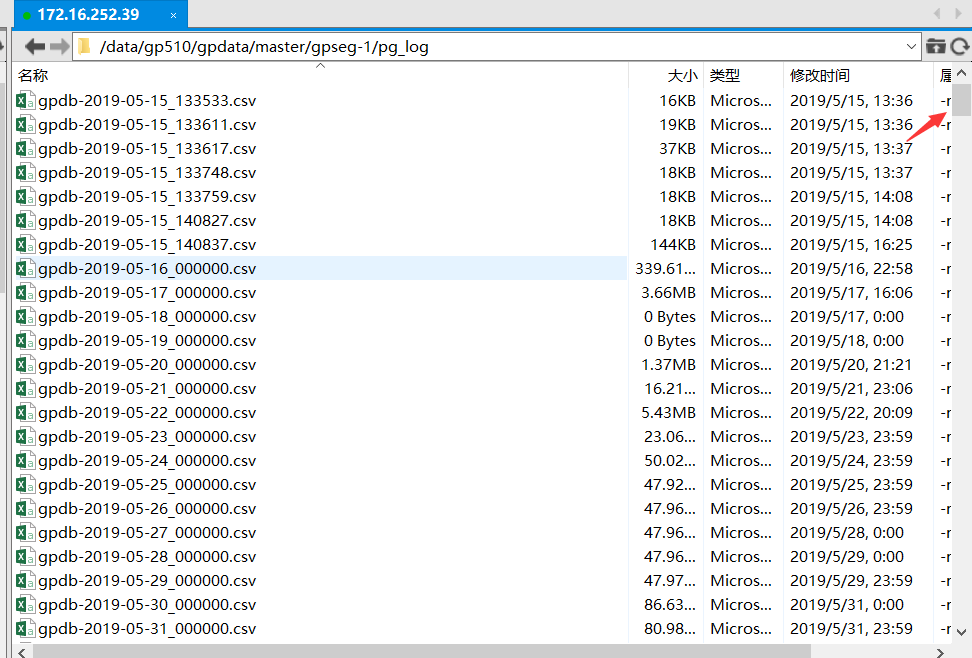
在目录下发现甚至有19年的日志存在,并且由于此次从5月8日开始启用新系统的ETL工具,该系统的ETL方式大致为:
- 查询源表数据;
- 根据源表结构和字段类型,创建临时表;
- 将源表数据插入到临时表;
- 从临时表取出数据,插入到目标表中。类似于
select * from temptable into xxx
由此看来,是因为日志未做清除策略,加上临时表很占用内存,都存放到了日志中,导致日志文件大小瞬间暴涨,连续运行几天之后,挤爆了磁盘空间。
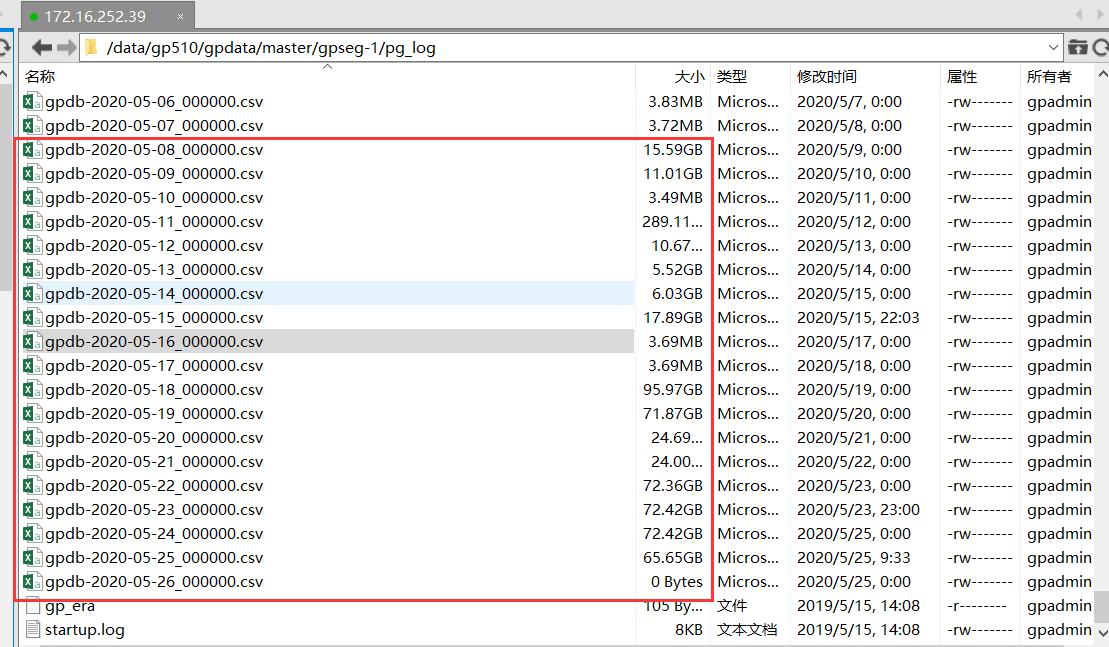
因为暂时无法修改ETL系统策略,只能修改greenplum的日志策略,调整为3天清除一次。编写如下的shell脚本
1 | #!/bin/sh |
-mtime代表修改时间,+3代表超过三天前的文件,为该脚本设置定时执行:
1 | [root@tdh39 gp510]# crontab -e |
保存上面的shell文件为log_task.sh,使用crontab -e进入编辑,添加一句0 0 * * * /data/gp510/log_task.sh(每日凌晨执行)并保存。使用crontab -l可以查看该调度。
重启crontab使配置时生效:
1 | [root@tdh39 gp510]# service crond restart |
查询缓存不足 statement_mem
设置每个查询在segment主机中可用的内存,默认125M。当扫描一张分区特别多的表时,会出现该错误ERROR: insufficient memory reserved for statement (memquota.c:228)
解决方法,可以通过修改配置文件并重启集群,也可以通过如下方式修改:
1 | su gpadmin |
gp重启步骤
1 | su gpadmin |