无锁队列
无锁也称为 LockFree,其实现原理是基于 CAS( compare and swap) 原子操作来保证多线程下共享资源的线程安全问题。
CAS(V,E,N)代表的是要更新的值V,预期值E,当且仅当要更新的值等于预期值时(V=E),将V的值设为N。CAS操作会返回一个boolean值,true表示交换成功,失败时进入循环,重新进行下一轮操作。
无锁队列则是使用 CAS 来实现的,且支持并发操作的队列。在阅读源码之前,我使用 Atomic 包里的原子类及网上的一些参考信息编写了一个使用数组实现的简易无锁队列。
代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96public class LockFreeQueue {
//队列元素
private AtomicReferenceArray items;
//容量
private volatile int size;
//入队次数
private AtomicInteger enCount;
//出队次数
private AtomicInteger deCount;
LockFreeQueue(int size) {
this.size = size;
//new Object[size+1],下标0当做哨兵元素,不使用,处理下标挺麻烦的
items = new AtomicReferenceArray(size+1);
enCount = new AtomicInteger(0);
deCount = new AtomicInteger(0);
}
//入队,更改队尾,入队次数和出队次数取模,可以很容易得到当前 head 和 tail 的下标
public boolean add(Object obj) throws Exception {
if (obj == null) {
throw new Exception("元素不能为null");
}
//新的 tail 位置
int newTailIndex = (enCount.get()+1) % size;
//用出队次数计算当前 head 位置
int headIndex = deCount.get() % size;
// tail 取的是+1后的模,两者相等时表示队列已满
if (newTailIndex == headIndex) {
System.out.println("队列已满," + obj + "入队失败!");
return false;
} else {
//CAS设置值
while (!items.compareAndSet(newTailIndex, null, obj)) {
add(obj);
}
//入队次数+1
enCount.incrementAndGet();
}
System.out.println("入队成功!" + obj);
return true;
}
//找到队首,出队。
public Object poll() {
if (enCount.get() == deCount.get()) {
System.out.println("当前队列为空,出队失败!");
return null;
}
int headIndex = (deCount.get()+1) % size;
Object obj = items.get(headIndex);
if(obj!=null && items.compareAndSet(headIndex,obj,null)){
//出队次数+1
deCount.incrementAndGet();
System.out.println("出队成功!" + obj);
return obj;
}else{
// cas 失败,或其余线程已出队成功,此处线程并发高会出现递归栈溢出。。。
return poll();
}
}
public void print(){
StringBuffer buffer = new StringBuffer("[");
for(int i=1;i<size;i++){
if(items.get(i)==null){
continue;
}else{
buffer.append(items.get(i)).append(",");
}
}
buffer.deleteCharAt(buffer.length() - 1);
buffer.append("]");
System.out.println("当前队列为:"+buffer.toString());
}
public static void main(String[] args) {
LockFreeQueue queue = new LockFreeQueue(10);
//弊端,数字调大后,容易出现栈溢出
IntStream.rangeClosed(1,20).parallel().forEach(i -> {
if (i % 2 == 0) {
try {
queue.add(i);
} catch (Exception e) {
e.printStackTrace();
}
} else {
queue.poll();
}
});
queue.print();
}
}
ConcurrentLinkedQueue
ConcurrentLinkedQueue 是 jdk 并发包中提供的无锁队列,它是使用单向链表来实现的,其类图结构大致如下:
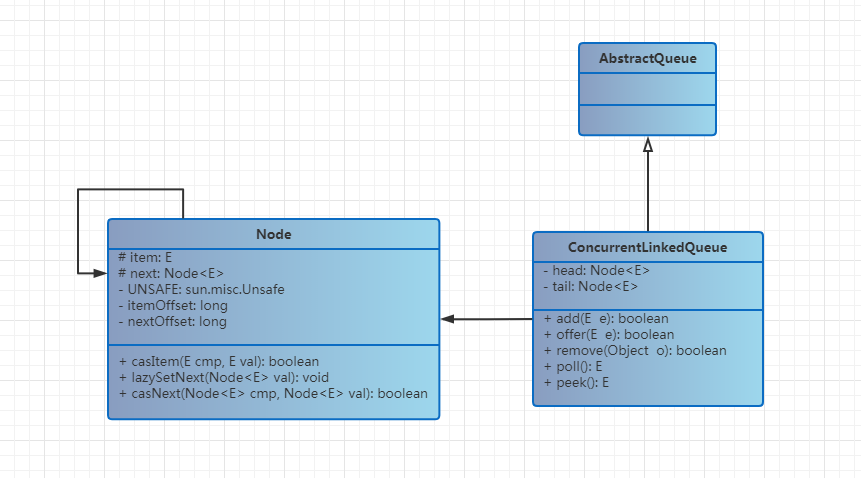
结合源码通过分析可知使用的数据结构是单向链表,同时定义了两个 volatile 的原子变量 head 和 tail 用于表示队列的头部和尾部,队列初始化时,会将头部和尾部指向哨兵节点(构造函数)。下述代码展示了其相关的基本属性:
1 | private transient volatile Node<E> head; |
有了内部类 Node 中提供的原子操作方法后,接下来看看其入队、出队等功能是如何实现的。
1.offer 入队操作:
入队的核心是通过 CAS 设置修改 tail.next 的值,成功则加入队列,失败的线程则继续循环,直到成功。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34public boolean offer(E e) {
//1.检查对象是否为空,null 抛出异常
checkNotNull(e);
//2.新建节点为 newNode
final Node<E> newNode = new Node<E>(e);
//括号里的两行只会在循环开始时执行一次。 t 和 p 都是循环内的局部变量,估计可以优化性能吧
for (Node<E> t = tail, p = t;;) {
//3.执行入队操作
Node<E> q = p.next;
//4. q 为空了,所以 p 是最后一个节点,执行插入
if (q == null) {
//5.使用 cas更新尾节点为newNode
if (p.casNext(null, newNode)) {
//6. cas 更新成功,尾节点已变为 newnode,返回 true,同时判断是否更新 tail 的位置
// tail 是间隔一个元素进行更新的,不是每次入队都会刷新 tail.
if (p != t) // 跳跃更新头结点 head 的位置
casTail(t, newNode); // Failure is OK.
return true;
}
// Lost CAS race to another thread; re-read next
}
//7. q 是 p 的 next 指针,两者相等说明此时为自引用状态,重新找到 head 的值。这一步判断是因 poll 引起的
else if (p == q)
//这句话是可以返回 false 的,这与 JVM 的压栈顺序有关,
//执行时 t 的值会先被读取压入栈底,随后读取 tail 赋给 t 将赋值结果入栈,
//最后取两者进行对比。因为涉及多线程操作,在入栈后赋值前若 tail 的值因其它线程发生了变化。
//那么取赋值后的 t 为 head ,否则 head 还是原来的 head
p = (t != (t = tail)) ? t : head;
else
// 8.因其它线程先 cas 成功,所以需要重新找到尾节点尝试新一轮的入队
p = (p != t && t != (t = tail)) ? t : q;
}
}
假设一开始队列为空,初始化后第一次入队操作时,成功运行节点1、2、3的代码后其状态如下:
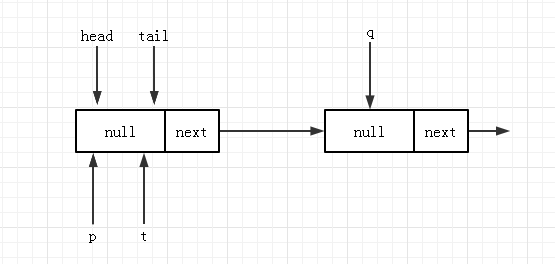
到节点 4 判断 q == null 时,若两个线程 A,B 并发的判断成功了,都会进入节点 5 处的代码,假设线程 A 先 进行 CAS 更新 tail 成功,将 newNode 加入到了队列,并且,由于 p==t,不会触发 tail 的位置更新。此时队列状态为:
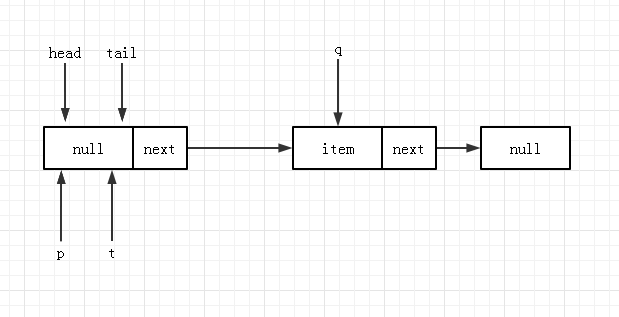
与此对应,线程 B 也进行 CAS 但因 A 已经成功,所以 B 的交换会返回 false,进入下一轮循环,并重新运行到节点 4 的位置,此时由于 q!=null 且 p!=q 所以会运行到节点 8,将 q 赋值给 p。此时队列状态更新为:
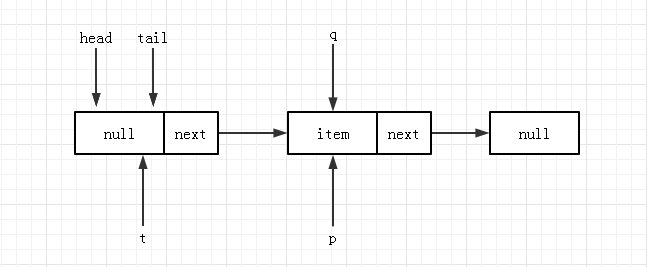
线程 B 继续下一轮循环,现在找到了正确的 tail 为 p,运行到 4 时,判断 q = p.next 为空,随后进入到 5 的位置,进行 CAS 操作且将线程 B 的 newNode 加入到队列中,此时队列状态为:
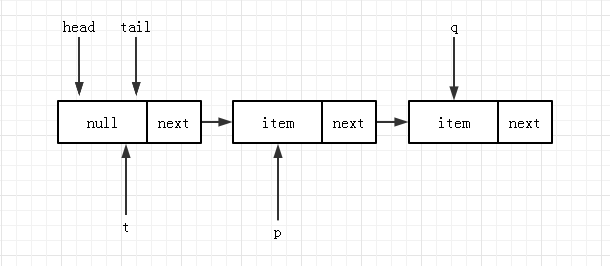
由于 p!=t ,所以触发 tail 结点更新,队列状态变更为:
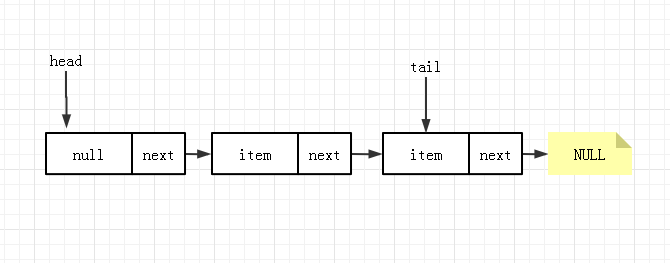
经上述流程后, 1-8 中除 7 以外的都已经执行过了,那么节点 7 是在什么时候执行的呢。其实 7 是在其它线程进行 poll 后或 remove 后出现的一种特殊情况才会发生,其队列状态如下:
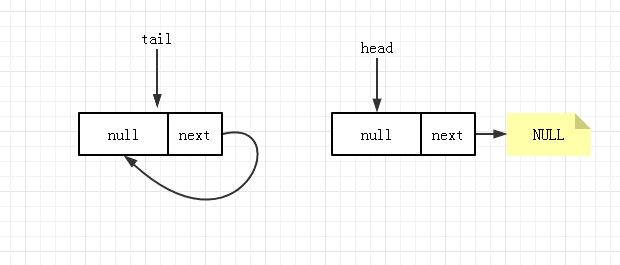
此时进行 offer 操作运行到 4 时的队列状态为下图所示( q==null 为 false,有自引用所以不是 NULL ):
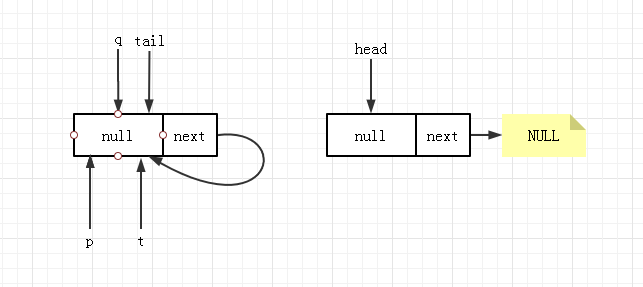
随后 7 判断到 p == q ,将 head 的值赋给了 p,下一轮循环再次运行到 4 时的队列状态变为了:
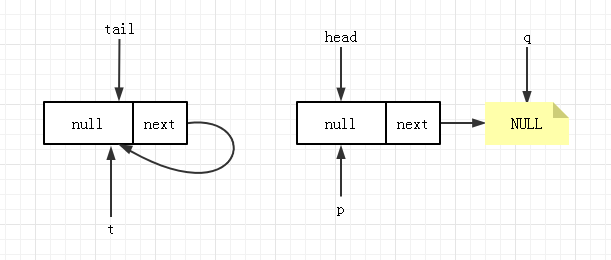
此时的 q ==null 返回 true,进入 5 ,若没有线程在做 offer 操作,则将新节点加入到队列。
由于 p != t 所以设置新节点为 tail,队列状态变为:
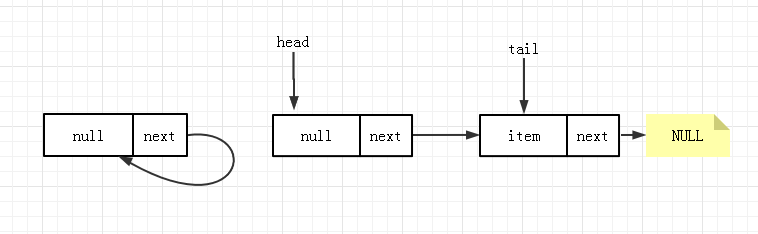
最后,自引用节点(自引用是在 updateHead 方法中产生的)会由于没有对象引用它,下一次GC时会被自动清理。
2.poll 出队操作:
出队的核心是找到队首 head,并将 head 的值返回,并通过 CAS 将 head 设为 NULL 。
1 | public E poll() { |
上述的代码一共分为了 7 个部分,现在假设队列一开始为空,线程运行到节点 3 的时候,队列状态为如下:
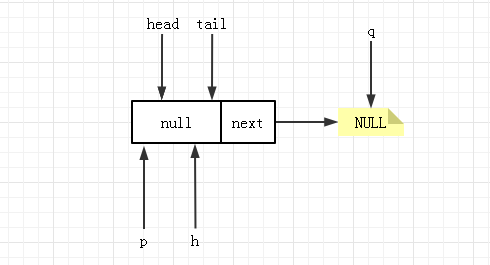
此时,item 的值为空,且 (q = p.next) == null 返回 true ,队列为空,代码进入到节点 5 交换头结点,但由于h和p是相等的,所以不会变化,返回 null 值。
倘若当线程A运行到节点 5 时,线程 B 已经入队了一个元素。队列的状态变为了:
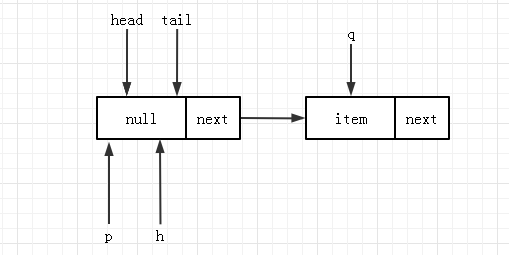
此时节点 5、6 都会判断失败,代码进入到节点 7,将 q 的值赋给了 p,并进入下一轮循环,此时队列状态更新为:
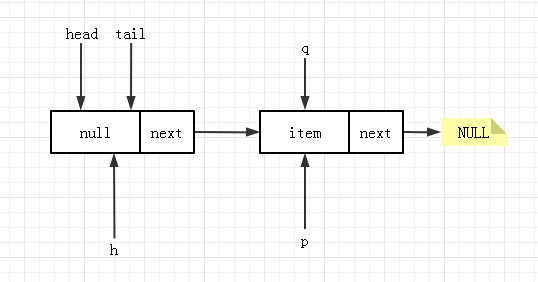
当代码再次运行到节点 3 的时候,队列状态为下图所示:
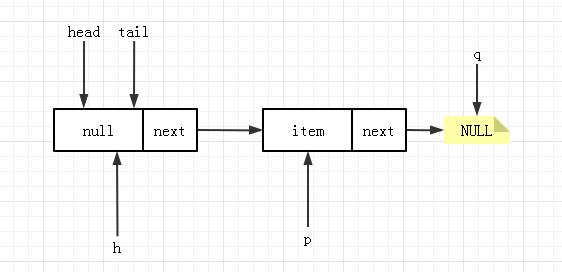
节点 4 判断 item!=null,且此时没有其它线程干扰的话,CAS 成功, 由于 p!=h 所以更新头结点的位置为 p,队列状态更新为:(这时候,tail 的状态就是上面 offer 操作时节点7对应的状态。)
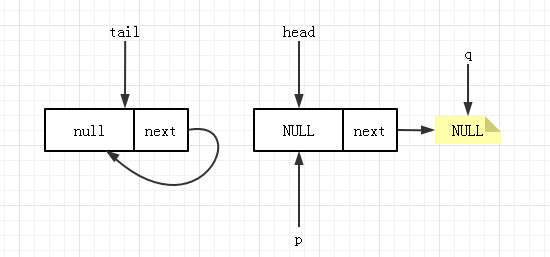
对于 poll 操作的节点 6,也是一种并发场景,它出现在当线程 A 执行第四步,CAS 刚成功,但还没有更新头结点。此时线程 B 刚开始 poll 操作,得到 p 指向 head,队列状态为如下:
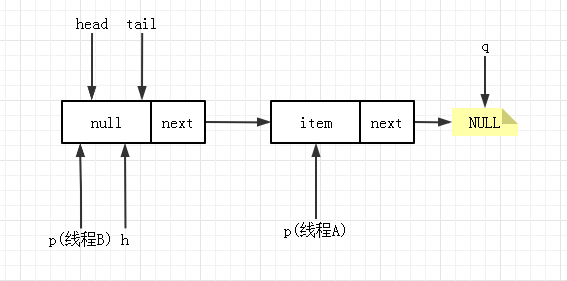
这时,线程A 更新 head 成功退出循环,原来的元素变成自引用,队列状态变为:
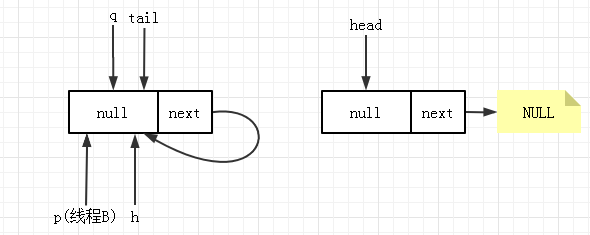
当线程 B 运行到 6 时,就会发生 p== q,跳回到循环起始位置,重新获取 head 出队。
3.peek获取队首
peek 的功能是返回队首元素,但不出队。所以比起 poll 而言,本质就是少了 CAS 操作而已。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public E peek() {
restartFromHead:
for (;;) {
for (Node<E> h = head, p = h, q;;) {
//1.存储节点值
E item = p.item;
//2.判断节点
if (item != null || (q = p.next) == null) {
updateHead(h, p);
return item;
}
//3.处理自引用
else if (p == q)
continue restartFromHead;
else
//4.重新定位头结点的位置
p = q;
}
}
}
由于初始时,head 和 tail 指向的是哨兵节点。peek 进行第一次循环时得到的 item必定为 null,如果队列中没有元素,那么 2 判断成功,更新头结点,但 h==p 所以没有变化,返回 null 值。
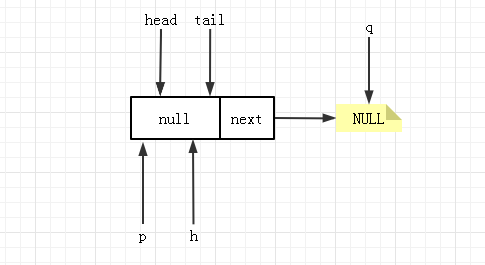
如果队列中有元素,代码进入到 4,更新 p 的位置。下次运行到 2 时,item!=null,更新头结点成功,并返回真正的 head 值。
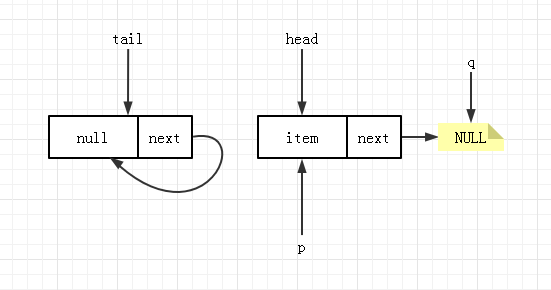
出现自引用时,更新头结点位置与 poll 的方式相同,不再说明。
4.updateHead更新头结点
该方法用于交换头结点的位置。1
2
3
4
5final void updateHead(Node<E> h, Node<E> p) {
//当 h!=p 时,且 cas 更新头节点成功,执行 lazySetNext,将 h 指向 h 自己,也就是自引用。
if (h != p && casHead(h, p))
h.lazySetNext(h);
}
上述说到自引用的时候可能会有疑惑,其实就是因为 updateHead 方法中 lazySetNext 的原因。
5. first 取第一个元素
1 | Node<E> first() { |
6.其余方法
1 | //获取下一个元素 |
tips
head/tail并非总是指向队列的头 / 尾节点,而是采用了一种hop two nodes at a time的
方式,每隔一个节点更新。或者在进行其他的操作的时候变相更新位置。(事实上,remove、peek、first、poll都会更新head的位置)。由于队列有时会处于不一致状态。为此,
ConcurrentLinkedQueue使用 三个不变式 来维护非阻塞算法的正确性。为了有利于垃圾收集,队列使用了特有的
head更新机制;通过setLazyNext将原节点改为自引用,促进垃圾回收。
为什么使用 hop 的方式更新 head 和 tail
其实一直将 tail 节点作为队列的尾节点是可以的,但这样会导致每次入队后,都要用 CAS 更新 tail,如果能减少 CAS更新 tail 的次数,就能变相的提高入队的效率。但如果每次 hop 的距离过大,就会加长定位尾节点的时间,所以源码的实现里是跳了一个位置。
总结自《并发编程艺术》、和许多博文(orz)。