1. 文档学习
本周文档阅读内容大模块为 Search API 和 Indices API,重点内容包含以下模块
doc_value、explain、collaspace及index boost;特殊查询
rescore query、script_fields、inner_hits以及post_filter;分页查询
from+size、scroll、search_after;search_type之query_then_fetch、dfs_query_then_fetch;sort、source_filter过滤;search_template、explain与profile_API。索引操作
sharink、split、rollover、open/close(不常用)- 别名
index aliases与索引模板index template(疑问,template的version具体什么场景下使用?) synced_flush与force_merge
2. Search API总结
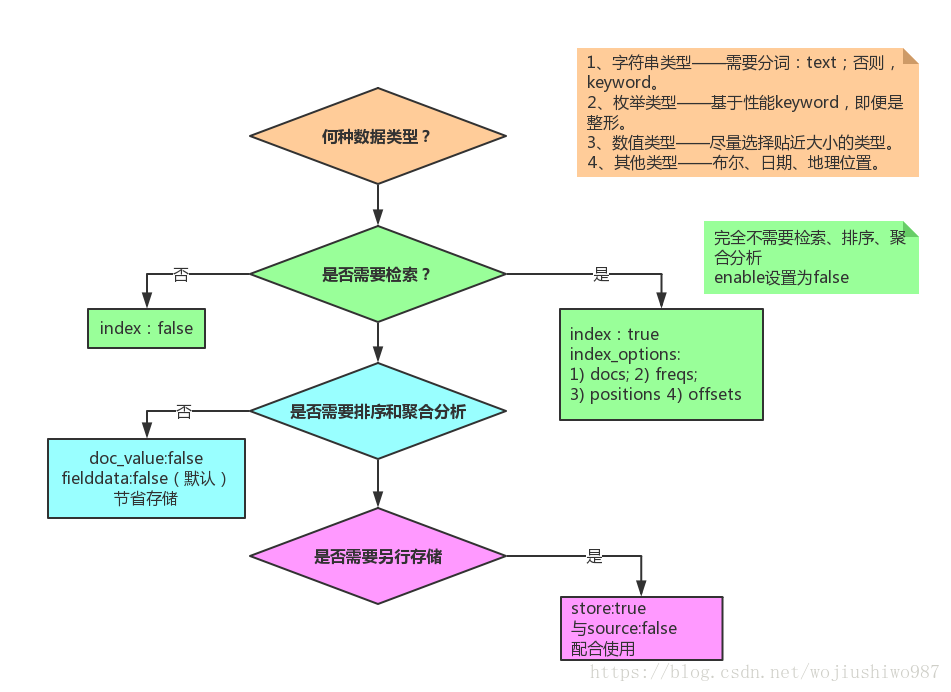
2.1 index、doc_values、store 的区别
2.2 rescore query
重新查询,默认与 query中的得分进行加法计算,使用multi_rescore 时,后者会看到前一个 rescore 算分后的结果集,所以通常会先给定一个大的 window_size,第二个 rescore 再缩小 window_size 的方式。例如:
1 | GET twitter/_search |
2.3 script_fields的取值方式
script_fields 有两种取值方式 ,doc['my_field'].value的方式会通过 term 加载整个字段到缓存中,使得 script 的执行更快,但占用的内存也更多,同时这种写法也只支持简单的值字段,无法取到 JSON Object 对象。官方的推荐做法仍旧是使用 doc[...],因为params['_source']['my_field'] 的方式在每次处理时都会去加载 _source,执行会慢很多。
1 | POST test/_doc |
2.4 post_filter
应用场景:
- 结果中再次搜索(不推荐,会导致
filter_query的缓存效果失效) - 聚合后过滤返回的
hits的结果集
1 | // 索引定义、数据初始化 |
结果中再次搜索 post_fiter
用户第一次搜索
gucci、基于第一次的结果中,再次搜索颜色为red,此时的查询dsl为:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
{
"query": {
"bool": {
"filter": [
{
"term": {
"brand": "gucci"
}
}
]
}
},
"post_filter": {
"term": {
"color": "red"
}
}
}
post_filter 先聚合,再过滤 hits
以下 dsl 的查询逻辑为:先筛选所有 brand 为 gucci 的数据,然后按照 model 进行聚合。子聚合在父聚合的基础上,筛选颜色只为 red 的数据并进行二次聚合;由于此时返回的 hits 中包含的是父聚合中的所有数据,于是通过 post_filter 将其设置为只返回子聚合的数据
1 | GET shirts/_search |
2.5 from+size、scroll、search_after对比
from + size适用于普通的分页查询,也不需要深度分页,支持随机翻页,数据是实时的;scroll属于索引快照数据,通过不停地滚动查询来遍历所有数据,适合深度分页,但不具有实时性,当滚动开始后直到结束也不会发生变化;search_after,通过具备唯一性的属性来排序,按照排序值来实现翻页效果,适合深度分页,并且数据实时的。但不能进行随机翻页,只能一页一页的展示。
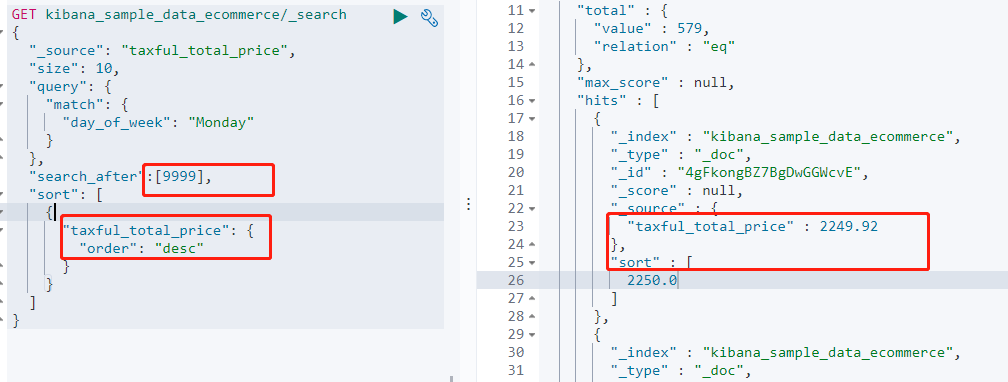
需要注意的是 : search_after 需要指定唯一字段为排序依据,否则同分值的会被过滤掉。
如下所示的search_after 是通过 taxful_total_size 排序后的数值进行翻页,当出现金额相同的情况时,两条数据都会被过滤掉,所以应该在 sort 和 search_after 中都加上类似 id 的唯一字段作区分。
2.6 Nested、Join、Object类型的区别
创建映射mapping,两个字段分别为 nested 和 object
1 | PUT nested_object_test |
索引一条数据
1 | //采用数组格式,分别放两个字段存入一条数据 |
搜索对比
检索同时满足 username = Tom ,age=30 条件的数据,正常情况下是没有结果的,而 object 字段的检索会返回结果,其本质原因是 object 类型在存储时会进行扁平化处理,即上述测试数据在存储时被处理为了:
username: [“Tom smith” , “William smith”], age: [20,30]
使用 Nested 嵌套对象时则不会出现该情况,Nested 数据类型允许对象数组中的对象被独立索引,存储时会分为多条 lucene 文档 (即,上述的测试数据会分为两个隐藏文档 ,每一个都存储着对应的 username 和 age ,最后召回时进行 join,所以效率也相对更低)
1 | //错误结果 |
Join类型 的性能不太好,nested 与 object 相比性能会低几倍,join 在 nested基础上会再低几倍。
| 对比 | Object | Nested | Join |
|---|---|---|---|
| 优点 | 速度快,性能好 | 文档存储在一起,性能较好 | 父子文档独立更新,互不影响 |
| 缺点 | 不支持数组字段的组合检索 | 更新时需要整个文档一起更新 | 内存占用多,读取性能差 |
| 场景 | 不需要对 object 数组查询、聚合 |
查询多,子文档偶尔更新 | 子文档更新频繁 |
nested的查询。聚合都需要使用nested_query;
Join需要通过parent_id、has_parent、has_child查询,且父子文档需要在同一分片上(使用routing)
需要注意的是,has_child 查询筛选的是子文档内容,然后返回父文档,通过 inner_hits 可以同时返回父子文档。has_child 查询的相关性算分,是由命中的 child 影响的。同时排序方式也和常规的 sort 不同,需要通过 score_mode 来影响最终的父文档排序。( inner_hits 中的排序可以直接使用常规 sort )
none,默认avg、max、min、sum;分别表示根据子文档得分的平均值、最大值、最小值、求和来排序
Join 的语法案例:
1 | // 创建索引 |
官方文档: has_child 的排序问题(has_parent也类似)
2.7 search_template 与 render template
search_template 的功能主要是用于工程代码和搜索解耦,维护人员定好 search_template 的基础结构和参数后,程序即可编写,当涉及到搜索调整,在参数没有更改的情况下,只需要调整 template 即可。
1 | POST _bulk |
3. indices API 总结
open/close、shrink、split、rollover 等API 不在考试范围内,暂且跳过。
3.1 索引别名 index aliases
别名概念可以类比数据库的字段别名,起到一个昵称的作用。
index aliases可以指定多个索引,所以也可以通过别名来检索多个index;index aliases的范围可以是整个索引,也可以是一部分数据
1 | // add 表示增加别名,remove 表示移除别名,remove_index 则等同于 delete_index |
3.2 索引模板 index template
索引模板可以用于数据量非常大,需要进行索引生命周期管理,按日期划分索引的场景,或者想要提取多个索引之间的共同字段
1 | // 索引模板样例 |
索引模板其实是可以使用变量的!,以下案例中展示了动态添加别名。{index} 会在索引创建时替换为实际的索引名称
1 | PUT _template/template_1 |
3.3 synced flush
sync flush 是 Elasticsearch 提供的一种机制,当一个分片在 5 分钟内没有收到任何 indexing 操作时,会被标记为 inactive 非活跃状态,然后启用 synced flush,给每一个分配标记一个唯一的 sync_id,这个 id 在集群恢复(或者重启时)可以快速检测两个分配是否相同,在这种情况下,可以无需复制 segment 段文件,以加快恢复速度。synced_flush说明
对于无需更新,或者很少更新的数据会很有用
1 | //检查是否有syncid 标记 |
手动执行 synced flush 后会返回成功数量、失败数量
3.4 forcemerge 段合并
对 Elasticsearch 的存储内容进行逐层拆解后是这样的:
index—>多shard—>多lucene—–> 多segment
默认情况下每一个 refresh_interval 产生一个 segment。后台也会有进程自动进行 merge,如下的指令表示强制进行 merge,max_num_segments 指定了合并后的段个数
only_expunge_deletes 参数表示把标记为 delete 的数据进行 merge (可以理解为真正删除,默认会等 60s )
1 | POST index_name/_forcemerge?max_num_segments=1&flush=true&only_expunge_deletes=true |
index.merge.scheduler.max_thread_count: 限制 merge 的并发线程数量,根据 cpu 核数修改。
index.merge.policy.expunge_deletes_allowed: 可以限制段合并的阈值,当删除的比例低于该阈值时,段合并不会生效。
4. tips
es 7.x为了提高性能,在命中数据大于1000时,不会返回准确的命中总数,并指出数据总量是gte 10000的,设置track_total_hits:true可以解决该问题,也可以将该参数设置为一个固定的数值,ES会返回gte该数值的说明;返回
version,可以设置version:true;sort可以对数组类型进行排序,例如:返回数组的平均值。或最小值;副本虽然影响写入速度,但是可以增加查询速度和数据安全性,因为查询可以在任一副本上获取到结果;
query_then_fetch与dfs_query_then_fetch都是分两阶段,从不同的分片查询X条数据,最后汇总取top X区别在于dfs方式会在第一阶段计算分布式的词频,以得到更准确的相关性得分;explain API用于查看相关性算分的详情,而profile API则是用于查看每个步骤的执行耗时。默认不需要执行,特殊情况下可以手动执行的
dsl语句:1
2
3
4// 1.清除缓存
POST /twitter/_cache/clear
// 2. flush
POST /twitter/_flush`,
