1. 文档学习
本周阅读内容为 cat API、cluster API、query API 部分, 以及 script 和 mapping 的小章节内容。 Aggregatins 暂时跳过了(这一章我一直觉得很难 orz… 最后再来慢慢啃吧),这周总结的重点内容如下:
cluster reroute、cluster update settingsCompound queryfull text queryscriptingmapping
2. cat API、cluster API总结
2.1 常用的状态查看 API
1 | // 查看集群健康: |
2.2 _cluster/reroute
reroute 一共包含以下几种指令:
move,将分片从一个节点移至另一个节点,已经分配成功的shard只能使用move指令;cancel,取消分片的分配, 通常用于取消恢复中recovery状态的分片分配;allocate_replica,仅用于unsigned的副本分配,。
在 uri 中添加 ?retry_failed 可以自动失败重试,重试次数默认为 5 , 通过修改集群配置参数 index.allocation.max_retries 可以进行调整1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33GET _cat/shards/test2?v
// response-----------
index shard prirep state docs store ip node
test2 0 r STARTED 1 4.1kb 172.25.17.58 node3
test2 0 p STARTED 1 4.1kb 172.25.17.87 node2
# 我这里先查询到 shard 0 的主分片分布在 node2上,然后通过 reroute 移动到 node1 上。
POST _cluster/reroute?retry_failed
{
"commands": [
{
"move": {
"index": "test2",
"shard": 0,
"from_node": "node2",
"to_node": "node1"
}
}
]
}
# 分配 unsigned 的副本
POST _cluster/reroute?retry_failed
{
"commands": [
{
"allocate_replica": {
"index": "index_name",
"shard": 0,
"node": "node2"
}
}
]
}
强制分配不可恢复的错误
除以上指令之外,还有两个特殊的命令,这些命令允许将主分片 reroute。但是使用时需要特别小心,因为主分片的分配通常是由 Elasticsearch 自动处理的。无法自动分配主分片的原因包括:
- 创建了一个新索引,但是没有满足分配决定者的节点。
- 在群集中的当前数据节点上找不到数据的最新分片副本。为防止数据丢失,系统不会自动将陈旧的分片副本提升为主副本。
以下两个命令很危险,可能会导致数据丢失。只有在无法恢复原始数据并且集群能够接受数据丢失的情况,考虑使用。对于网络波动或其他可恢复性的分配失败,应该考虑使用 retry_failed 进行重试。
allocate_stale_primary
将包含旧数据的副本升级为主分片。需要给定 index 索引名称(index)和分片(shard)参数。使用此命令可能会导致数据丢失。如果具有数据版本更高的节点稍后重新加入群集,则该节点的数据将被删除或被新创建的副本覆盖掉。为明确操作危险性,此命令要求将该标志 accept_data_loss 显式设置为 true 才能执行。
allocate_empty_primary
将空的主碎片分配给节点,需要给定 index 索引名称(index)和分片(shard)参数。使用此命令将导致完全丢失索引到该分片的所有数据(如果先前已启动)。如果具有数据副本的节点稍后重新加入群集,则该数据将被删除。为明确操作危险性,此命令要求将该标志 accept_data_loss 显式设置为 true 才能执行。
3. query API 总结
3.1 组合查询 compound query
bool query,包含了must、must_not、should、filter四种基础查询,自由组合;boosting query,权重查询,适用于 xx 公司、xx 集团等关键词区分权重的场景;constant_score,不需要相关性算分的场景(filter使用的就是constant score只不过分值为0);disjunction max,单个字段最匹配(类比multi_match的best fields效果)function score,自定义算分
bool query
组合查询:多条件之间可以自由拼装、嵌套
1 | GET index_name/_search |
boosting query
权重查询:返回满足 positive 查询的数据,对于该结果中同时也满足 negative 的数据进行评分降低操作。
- 例如检索企业名称这种数据中都带有【公司】、【有限公司】、【集团】之类的比较范的关键词;
- 或者在检索苹果时,【派、树、面包】这些相关性更低,而【苹果】公司相关性可能更高的场景。
1 | GET index_name/_search |
constant score
1 | GET index_name/_search |
disjunction max
对于普通的 match 查询而言,当多个字段都有匹配时,很可能就会比某个字段完全匹配的分数更高,而 disjunction max 则根据匹配度最完整的字段来做主要评分,其余字段只起到辅助评分的效果。下面的例子中所展示的 tie_breaker 就是指其他字段的得分系数:
1 | GET index_name/_search |
function score
function score 目前共包含以下几种:
script_score可以自定义脚本计算分数,由于script具有编译缓存机制,所以能抽取参数的情况下,尽量是抽取参数后使用固定脚本;random_score+seed可以用于随机推荐、排名场景;weight权重,我目前将它简单的理解为boost,很简单(略过);field_value_factor,可以应用在内容相同(相似),通过投票数、点赞数等其他字段影响分数的场景;decay functions大概用在附近位置、相近时间等,(有点类似于range_query的感觉,但分数计算会更加圆滑–>因为是通过衰减函数计算的)。
基础用法:
1 | GET kibana_sample_data_ecommerce/_search |
boost_mode 与 score_mode 的区别
多个 function 之间的算分为 score_mode,基础 query与 function_score 之间的算分为 boost_mode。
1 | GET /_search |
random_score + seed 的使用案例
当 seed 相同时,返回的随机分数是固定的,可以用于对不同的用户展示乱序结果,但同一个用户结果不变的场景
1 | POST /blogs/_search |
field_value_factor的使用案例
1 | GET /_search |
decay functions 衰减函数的使用案例
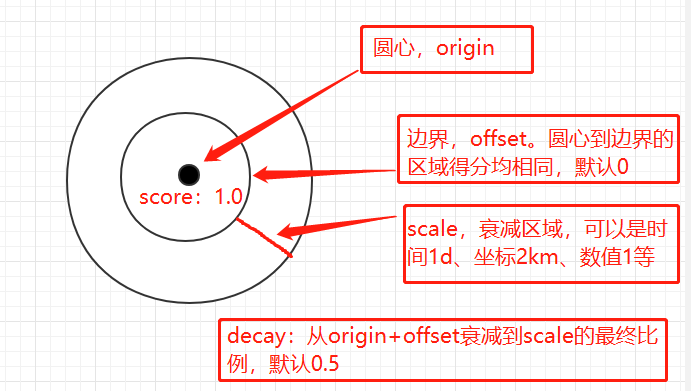
通过衰减函数对文档进行评分,函数的衰减速度取决于文档的数字字段值距用户给定原点的距离。类似于范围查询,分数变化更加的平滑,而不是固定的数值。
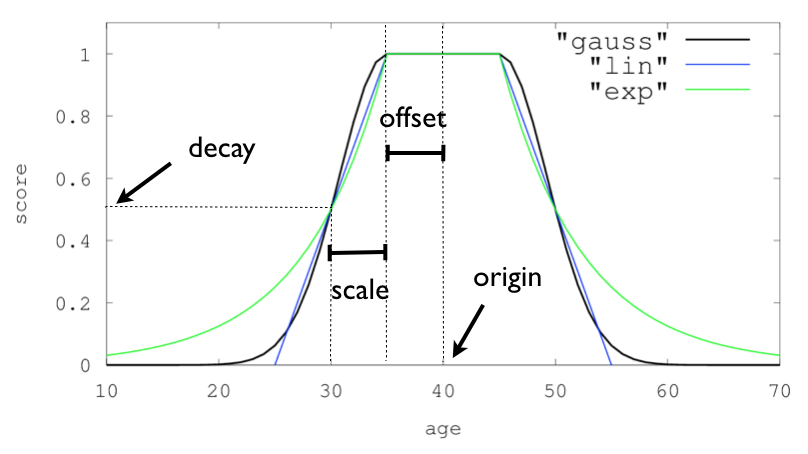
衰减函数的类型,包括 gauss 高斯函数、linear 线性函数、exp 指数函数三种1
2
3
4
5
6
7
8
9"gauss": {
//字段名
"location": {
"origin": "11, 12",
"scale": "2km",
"offset": "0km",
"decay": 0.33
}
}
decay_function 参数示意图:
三种衰减函数示意图:
官方案例说明:假设我们在一个小镇的中心搜索附近的酒店,我们希望离小镇中心越近越好,同时价格也是一个选择因素,例如有一个更便宜的,距离稍微远些也是可选项。
我们将搜索范围限定在 2km 以内,并且希望价格不高于 100 元。那么可以使用如下的衰减函数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// 价格
"gauss": {
"price": {
"origin": "0",
"scale": "100"
}
}
// 位置
"gauss": {
"location": {
// 假设中心坐标是 11,12
"origin": "11, 12",
"scale": "2km"
}
}
3.2 full text query
intervals(跳过)match、match boolean prefix、match phrase、match phrase prefix- multi match
- common term query
- query string 与 simple query string
match boolean prefix 和 match phrase prefix 的使用案例
1 | GET index_name/_search |
multi match
most_fields 等同于普通的 should + match 查询,各字段分值相加;best_fields 相当于 disjunction max 查询;cross fields 用于跨字段查询。
1 | // 字段名可以通过 ‘^’ 符号实现 boost 效果,* 实现字段通配符 |
common term query
这个 query 是为了解决普通 term_query 存在的问题而延伸的功能,在介绍 common term query 之前,需要先了解 term 查询的问题点:
常规的 term 查询,例如 the brown fox 这个词需要拆分三个 term ,分别是 the 、brown 以及 fox ,每个 term 都会查询所有的文档,对于 the 这种通用的定冠词可以匹配到大量的文档。它对于的相关性影响应该更低,所以 term 查询的处理方法是将 the 视为停用词,这样不仅减小了索引空间占用,也减少了扫描文档的数量。但是也带了一个新的问题,虽然 the 对于结果的相关性影响更小,但依旧对文档的总得分是有影响的。视为停用词之后则此部分不再贡献相关性得分了。同时也会影响召回率:例如 happy 和 not happy 的判断将会不准确。
common term query 将词分为两部分,more important(低频词) 和 less important(高频词)。查询时也分为两个步骤,先查找 more important 部分,此时返回的结果相对更少,然后查找 less important 部分,对相关性算分的贡献值更小,但不会查找全部文档,而是在 more important 的结果集中二次筛选。
如果所有的词都是 less important 的高频词,那默认情况下将通过 AND 将词语组合在一起进行一次查询。(可以通过 minimum_should_match 控制)。
判断关键词属于 more important 还是 less important 的参数是 cutoff_frequency(此参数是对于分片而言的) ,如下的查询中,词频超过 1% 的将作为 less important(高频词),高频词之间采用 OR 关联,低频词采用 AND 关联(match_query 也支持该参数,但不支持 *_freq_operator)。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38GET /_search
{
"query": {
"common": {
"body": {
"query": "nelly the elephant as a cartoon",
"cutoff_frequency": 0.001,
"low_freq_operator": "and",
"high_freq_operator": "or"
}
}
}
}
// 大致相当于
GET /_search
{
"query": {
"bool": {
"must": [
{ "term": { "body": "nelly"}},
{ "term": { "body": "elephant"}},
{ "term": { "body": "cartoon"}}
],
"should": [
{ "term": { "body": "the"}},
{ "term": { "body": "as"}},
{ "term": { "body": "a"}}
]
}
}
}
// 还可以增加 minimum_should_match 控制 or 匹配的个数
minimum_should_match: 2
// 或者
"minimum_should_match": {
"low_freq" : 2,
"high_freq" : 3
}
3.3 named query
可以用于判断具体是哪个查询条件命中了数据
1 | GET /_search |
4. scripting总结
script 可以用的地方很多,目前包括了 reindex、pipeline、update、update_by_query、script_score、script_fields、search_templatey 以及 script 聚合等。场景非常广泛。复习此部分时刚好解决了群里小伙伴的一个疑问
群友提问 script 如何实现 split字符串分割
场景数据如下,希望将 b 字段分割为数组存到新字段中,在 reindex 时发现 pipeline 可以实现,但使用 script 脚本时确报错编译失败:
1 | DELETE index_a/_doc/1 |
由于 painless 与 java 语言是类似的,经查看 String 类的 split 方法参数为正则 regex 表达式。所以直接使用 , 会编译失败,而使用 /,/ 正则表达式时则会提示需要设置 yml 参数 script.painless.regex.enabled: true ,默认情况下正则是关闭的。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39GET index_a/_doc/1
POST index_a/_update_by_query
{
"script":{
"source":"""
ctx._source.b_list = ctx._source.b.split(/,/)
"""
}
}
// 错误信息
{
"error": {
"root_cause": [
{
"type": "script_exception",
"reason": "compile error",
"script_stack": [
"... st = ctx._source.b.split(/,/)",
" ^---- HERE"
],
"script": " ctx._source.b_list = ctx._source.b.split(/,/)",
"lang": "painless"
}
],
"type": "script_exception",
"reason": "compile error",
"script_stack": [
"... st = ctx._source.b.split(/,/)",
" ^---- HERE"
],
"script": " ctx._source.b_list = ctx._source.b.split(/,/)",
"lang": "painless",
"caused_by": {
"type": "illegal_state_exception",
"reason": "Regexes are disabled. Set [script.painless.regex.enabled] to [true] in elasticsearch.yaml to allow them. Be careful though, regexes break out of Painless's protection against deep recursion and long loops."
}
},
"status": 400
}
另一种解决办法:使用 StringTokenizer 拆分
1 | POST index_a/_update_by_query |
5. mapping 总结
5.1 normalizer
normalizer 是用于解决 keyword 类型的数据规范问题的,例如某个字段设置为了 keyword 类型,但数据清洗时存在的不规范导致了两种数据 apple、Apple,由于 keyword 类型的性质,导致两者成为了不同的单词。
normalizer 会在数据写入之前进行统一处理,例如使用 filter: lowercase 将 apple 和 Apple 统一
1 | DELETE test_normalizer |
5.2 Dynamic mapping
dynamic_field_mapping1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44//日期推断
PUT my_index/_doc/1
{
"create_date": "2015/09/02"
}
GET my_index/_mapping
//关闭推断
PUT my_index
{
"mappings": {
"date_detection": false
}
}
PUT my_index/_doc/1
{
"create": "2015/09/02"
}
// 格式化
PUT my_index
{
"mappings": {
"dynamic_date_formats": ["MM/dd/yyyy"]
}
}
PUT my_index/_doc/1
{
"create_date": "09/25/2015"
}
// 数字推断
PUT my_index
{
"mappings": {
"numeric_detection": true
}
}
PUT my_index/_doc/1
{
"my_float": "1.0",
"my_integer": "1"
}
dynamic_template
- 字段类型匹配:
match_mapping_type - 字段名称匹配:
match、unmatch、match_pattern - 字段通配符:
path_match、path_unmatch1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36//match_mapping_type、match
PUT my_index
{
"mappings": {
"dynamic_templates": [
{
"longs_as_strings": {
"match_mapping_type": "string",
"match": "long_*",
"unmatch": "*_text",
"mapping": {
"type": "long"
}
}
}
]
}
}
// path_match
PUT my_index
{
"mappings": {
"dynamic_templates": [
{
"full_name": {
"path_match": "name.*",
"path_unmatch": "*.middle",
"mapping": {
"type": "text",
"copy_to": "full_name"
}
}
}
]
}
}
dynamic 的三种级别: true、false、strict,可以用在 properties 同级,也可以用在字段上:
1 | PUT index_name |
5.3 docvalue_fields查询、data_nanos类型
1 | DELETE my_index |
5.4 index_options
index_options 参数控制向倒排索引添加哪些信息,主要用于搜索和高亮。有下面四种参数:
docs仅索引文档的id,可以用于判断该term在这个字段是否出现过;freqs索引文档的 id 和 term 的词频。计算相关性得分时,词频高的term分数会更高 ;positions索引文档的id和term的词频以及term的位置信息。位置对于phrase这种短语查询很重要。默认情况下字段属性index:true都会使用positions,数字使用的是docs;offsets在positions的索引基础上增加了开始字符以及结束字符的偏移量,偏移量对于unified highlighter高亮(默认的高亮方式)来说可以加速高亮。
6. tips
集群的
settings设置优先级顺序为:transient > persistent > elasticsearch.yml;indices.query.bool.max_clause_count限制了单次查询的字段数量,默认为1024;fielddata用于开启text类型字段的聚合;script小技巧:1
2
3
4
5
6
7// 通过 random 获取随机数
Random random = new Random();
ctx._source.age = random.nextInt(100);
// 取当前日期、时间戳
ctx._source.birthday = new Date();
ctx._source.birthday = new Date().getTime();
