1. 文档学习
本周阅读了 Analyzer API、ingest API、Modules 三个章节,以及 xpack 的配置 https 访问部分,重点内容如下:
- 内置分词器,以及自定义分词器;
ingest数据处理;shard allocation与cluster allocaiton;- 跨集群检索
cross-cluster search; xpack角色配置、https配置
2. Analyzer 总结
分词器是对一串语句进行词语分割处理的组件,它由三个部分组成:
char_filter(针对原始文本处理,如去掉某些符号、处理html等)tokenizer按照规则,将上一步处理后的语句切分为单词token filter将切分后的单词进行加工(如转为小写、去除停用词增加同义词等等)
分词的流程也是严格按照 char_filter ---> tokenizer ----> filter 这样的顺序进行的。
分词测试 API:
1 | POST _analyze |
2.1 内置分词器
standard,默认分词器,按词切分,小写处理;simple,按照非字母切分,小写处理,dog's会被拆分为dog和s;stop,小写处理,过滤停用词the、a、is等,dog's会被拆分为dog和s;whitespace,按空格拆分,不做小写处理;keyword,不分词;pattern,正则分词,例如自定义通过逗号切分;language,常见语言分词,例如english;fingerprint,没看懂
2.2 常用内置 tokenizer
standard按词切分,保留数字;letter按非字母拆分,不保留数字lowercase与letter类型,新增加了转小写操作;whitespace按空格拆分;uax_url_email与standard类似,增加了识别邮箱和url等数据;NGram Tokenizer,滑动窗口分词,分词长度介于min_gram只max_gram之间。Keyword TokenizerPattern Tokenizer正则分割Path Hierarchy Tokenizer路径切割
1 | POST _analyze |
2.3 常用内置 token filter
asciifolding
ASCII 过滤器,去除不在 ASCII 中的特殊标点符号,保留大小写,示例:
1
2
3
4
5
6POST _analyze
{
"tokenizer": "standard",
"filter": ["asciifolding"],
"text": "Is This-<déja v'u"
}
length
分词长度过滤器。只保留长度介于 min 和 max 之间的 token 。1
2
3
4
5
6POST _analyze
{
"tokenizer": "standard",
"filter": [{"type": "length", "min":1, "max":3 }],
"text": "Is This-<déja v'u"
}
lowercase
将分词统一转为小写1
2
3
4
5
6POST _analyze
{
"tokenizer": "standard",
"filter": ["lowercase"],
"text": "Is This-<déja v'u"
}
uppercase
将分词统一转为大写1
2
3
4
5
6POST _analyze
{
"tokenizer": "standard",
"filter": ["lowercase"],
"text": "Is This-<déja v'u"
}
ngram
对分词结果进行再拆分,然后保留长度介于 min_gram 和 max_gram 之间的词1
2
3
4
5
6POST _analyze
{
"tokenizer": "standard",
"filter": [{"type": "ngram", "min_gram":3, "max_gram":4 }],
"text": "Is This-<déja v'u"
}
shingle
将分词结果进行单词组装并保留原分词结果。例如[We ,love ,apple] => [We ,love ,apple, We love , love apple];1
2
3
4
5
6POST _analyze
{
"tokenizer": "standard",
"filter": [{"type": "shingle", "min_shingle_size":2 }],
"text": "Is This-<déja v'u"
}
stop
过滤停用词,支持 stopwords 和 stopwords_path
word_delimiter
将分词结果再次按照 “下划线”、“横线” 等分隔符进行拆分1
2
3
4
5
6POST _analyze
{
"tokenizer": "whitespace",
"filter": ["word_delimiter"],
"text": "Is this-<déja v'u?"
}
multiplexer
在分词的相同 position 执行多个 filter,如果处理后的词和原词相同。则移除掉。否则保留原词和新词1
2
3
4
5
6
7
8
9
10
11
12
13
14
15POST _analyze
{
"tokenizer": "whitespace",
"filter": [
{
"type": "multiplexer",
"filters": [
"lowercase"
]
}
],
"text": "Is This-<déja v'u"
}
------result-------
[Is(is),This-<déja(this-<déja),v'u]
condition
条件过滤,下面的例子表示将长度小于 5 的词转为小写1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16POST _analyze
{
"tokenizer": "whitespace",
"filter": [
{
"type": "condition",
"filter": [
"lowercase"
],
"script": {
"source": "token.getTerm().length() < 5"
}
}
],
"text": "Is This-<déja v'u"
}
predicate_token_filter
移除不满足 script 条件的 token1
2
3
4
5
6
7
8
9
10
11
12
13POST _analyze
{
"tokenizer": "whitespace",
"filter": [
{
"type": "predicate_token_filter",
"script": {
"source": "token.getTerm().length() > 5"
}
}
],
"text": "Is This-<déja v'u"
}
stemmer、snowball
提取各种语言的词干,默认语言为english,去掉 ing、ed 等。两者提取的词干略有不同(例如 are ,stemmer 会提取为 ar ,snowball 则保持不变)1
2
3
4
5
6POST _analyze
{
"tokenizer": "whitespace",
"filter": ["stemmer"],
"text": "Is This-<déja doing"
}
stemmer_override
覆盖 stemmer 的自动提取词干,顺序需要在其他 stemmer 之前
1 | POST _analyze |
keyword_marker
保护 token 不被 stemmer 提取词干1
2
3
4
5
6
7
8
9
10
11
12
13
14POST _analyze
{
"tokenizer": "standard",
"filter": [
{
"type": "keyword_marker",
"keywords": [
"doing"
]
},
"stemmer"
],
"text": "What are you doing?"
}
kstem
english 的高性能 filter,必须所有的词均为小写状态才能使用
synonym
重点!!!,同义词处理
1 | POST _analyze |
支持同义词文件路径参数 synonyms_path ,文件案例如下1
2
3
4
5
6i-pod, i pod => ipod,
sea biscuit, sea biscit => seabiscuit
ipod, i-pod, i pod
foozball , foosball
universe , cosmos
lol, laughing out loud
reverse
将 token 字符串翻转过来
truncate
有点类似于 substring,将原 token 按照 length 长度进行截取。1
2
3
4
5
6
7
8
9
10POST _analyze
{
"tokenizer": "standard",
"filter": [{
"type":"truncate",
"length":3
}
],
"text": "What are you doing?"
}
unique
相同的 token 只保留一个,设置 only_on_same_position:true 之后则只会移除在相同位置的,默认 false。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16POST _analyze
{
"tokenizer": "standard",
"filter": ["unique"],
"text": "What are you doing? are you doing?"
}
POST _analyze
{
"tokenizer": "standard",
"filter": [{
"type":"unique",
"only_on_same_position":true
}],
"text": "What are you doing? are you doing?"
}
limit
限制分词个数,由 max_token_count 控制,默认为 1。consume_all_tokens:true试了下没什么用1
2
3
4
5
6
7
8
9
10
11POST _analyze
{
"tokenizer": "whitespace",
"filter": [
{
"type": "limit",
"max_token_count": 2
}
],
"text": "What are you doing?"
}
keep
keep_words 只留下指定的词, keep_types 留下指定类型的词( 通过 mode 可以指定 exclude 模式)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24POST _analyze
{
"tokenizer": "standard",
"filter": [{
"type":"keep",
"keep_words":["this"]
}],
"text": "Is this 123"
}
POST _analyze
{
"tokenizer": "standard",
"filter": [
{
"type": "keep_types",
"mode": "exclude",
"types": [
"<NUM>"
]
}
],
"text": "Is this déja v'u 234"
}
apostrophe
撇号处理器,去掉 ' 之后的字符,例如 don't => don1
2
3
4
5
6
7
8POST _analyze
{
"tokenizer": "standard",
"filter": [
"apostrophe"
],
"text": "d'uuuuu"
}
fingerprint
对 token 排序并去重
2.4 常用内容中 char filter
html_strip char filter
顾名思义,在原文本基础上过滤 html 标签;通过 escaped_tags 可以自定义不需要处理的标签。1
2
3
4
5
6
7
8
9
10
11
12POST _analyze
{
"tokenizer": "standard",
"filter": [
"asciifolding"
],
"char_filter": [{
"type":"html_strip",
"escaped_tags":"span"
}],
"text": "<div><span>déja</span></div>"
}
mapping char filter
在原文本基础上进行字符映射,例如将 and 转为 & ,定义时至少要声明 mappings 或 mappings_path 中的其中一个。
1 | POST _analyze |
pattern replace char filter
使用 java 正则表达式进行文本替换,正则写的很糟糕的话,会导致运行慢、节点宕机、Stack Overflow 等一系列问题。下面是一个替换数字 - 连接符为 _ 的案例:1
2
3
4
5
6
7
8
9
10
11
12POST _analyze
{
"tokenizer": "whitespace",
"char_filter": [
{
"type": "pattern_replace",
"pattern": """(\d+)-(?=\d)""",
"replacement": "$1_"
}
],
"text": "My card is 123-456-789"
}
还有个群友提问到的场景,如何将 babyShoes 拆分为 baby 和 shoes,下面是解决办法。(这里拆分后会有新问题,高亮位置不正确,因为正则映射后,原词的 position 位置被我们改动了)1
2
3
4
5
6
7
8
9
10
11
12
13POST _analyze
{
"tokenizer": "whitespace",
"char_filter": [
{
"type": "pattern_replace",
"pattern": """(?<=\p{Lower})(?=\p{Upper})""",
"replacement": " "
}
],
"filter": ["lowercase"],
"text": "The fooBarBaz method"
}
3. 跨集群检索
跨集群检索允许只发送一个请求同时查询多个集群上的数据
3.1 跨集群检索案例
使用跨集群检索之前,需要先配置 remote_server ,方式如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24PUT _cluster/settings
{
"persistent": {
"cluster": {
"remote": {
"cluster_one": {
"seeds": [
"127.0.0.1:9300"
]
},
"cluster_two": {
"seeds": [
"127.0.0.1:9301"
]
},
"cluster_three": {
"seeds": [
"127.0.0.1:9302"
]
}
}
}
}
}
配置好 remote_server 之后就可以直接进行查询了:1
2
3
4
5
6
7
8GET /twitter,cluster_one:twitter,cluster_two:twitter/_search
{
"query": {
"match": {
"user": "kimchy"
}
}
}
通过以下设置,可以选择性的跳过由于某个集群不可用,而引起的查询报错问题:1
2
3
4
5
6PUT _cluster/settings
{
"persistent": {
"cluster.remote.cluster_two.skip_unavailable": true
}
}
3.2 cross-cluster search(CCS) 是如何工作的
跨集群的检索肯定会涉及到集群之间的通信,而任何网络问题或者请求延迟都会使查询变慢。为了避免 cross-cluster search 的慢查询问题,在发送请求时 Elasticsearch 提供了以下两种策略:
Minimize network roundtrips,默认情况下,Elasticsearch减少远程集群之间的网络往返次数,这样可以减少网络延迟对搜索速度的影响。但是,Elasticsearch不能减少大型搜索请求(例如包含Scroll或inner_hits的请求)的网络往返次数。(该分多次的还是得分多次查询….)Don’t minimize network roundtrips,对于scroll和inner_hits这类检索,Elasticsearch可以通过批量outgoing和ingoing的方式来访问远程集群。通过在请求中添加?ccs_minimize_roundtrips=false参数可以关闭请求数量压缩,速度较慢,但适用于低延迟的网络环境。
Minimize network roundtrips 检索的步骤:
- 将跨集群搜索请求发送到本地集群。该集群中的协调节点接收并解析该请求;
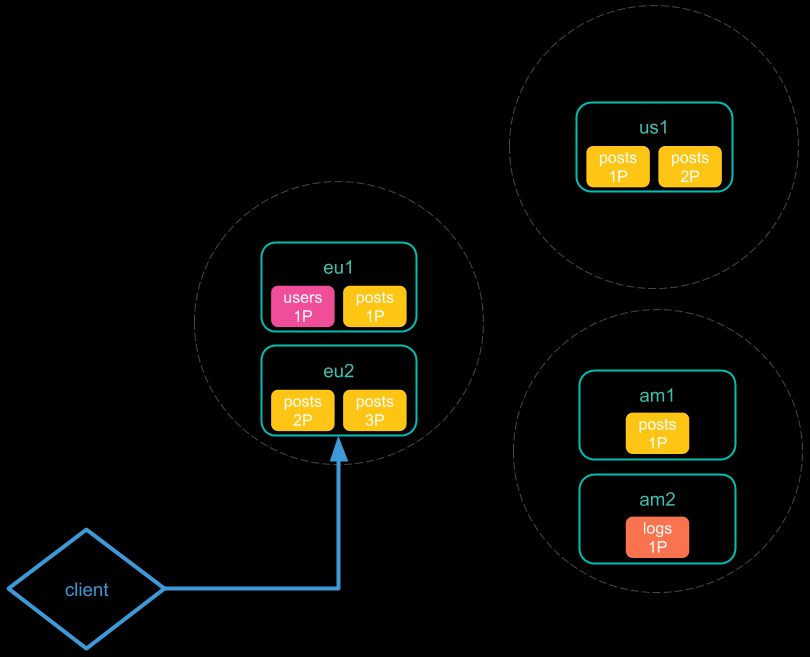
- 协调节点向每个集群发送单个搜索请求,包括其自身的搜索请求。每个集群独立执行搜索请求;
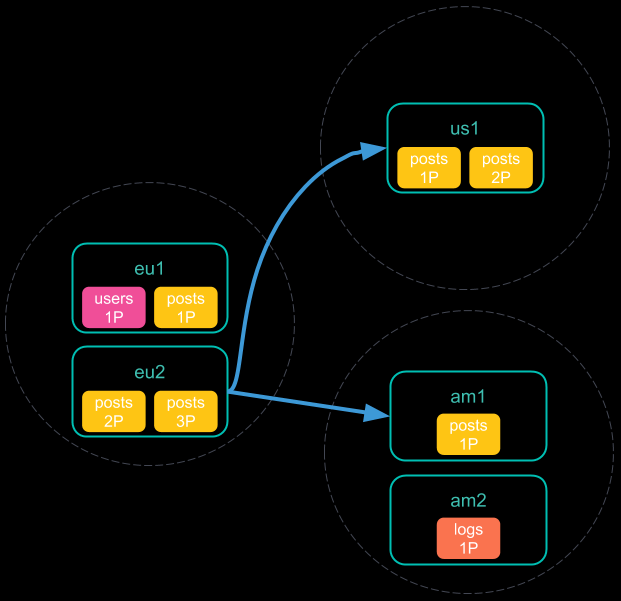
- 每个远程集群将其搜索结果发送回协调节点;
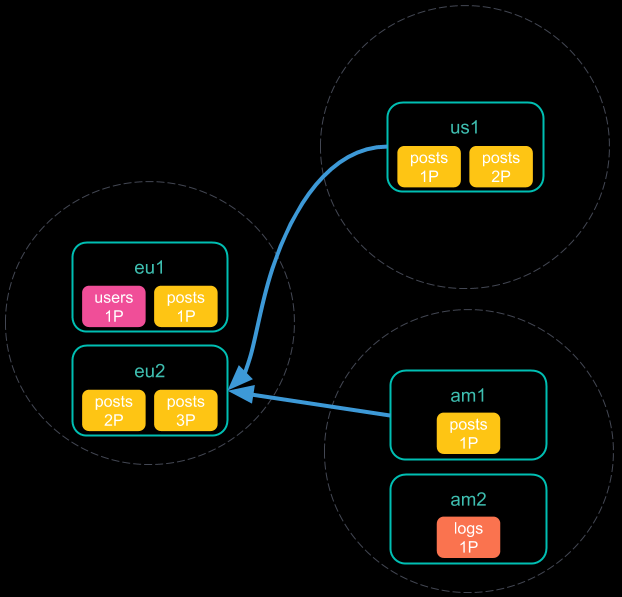
- 从每个集群收集结果之后,协调节点将在跨群集搜索响应中返回最终结果。
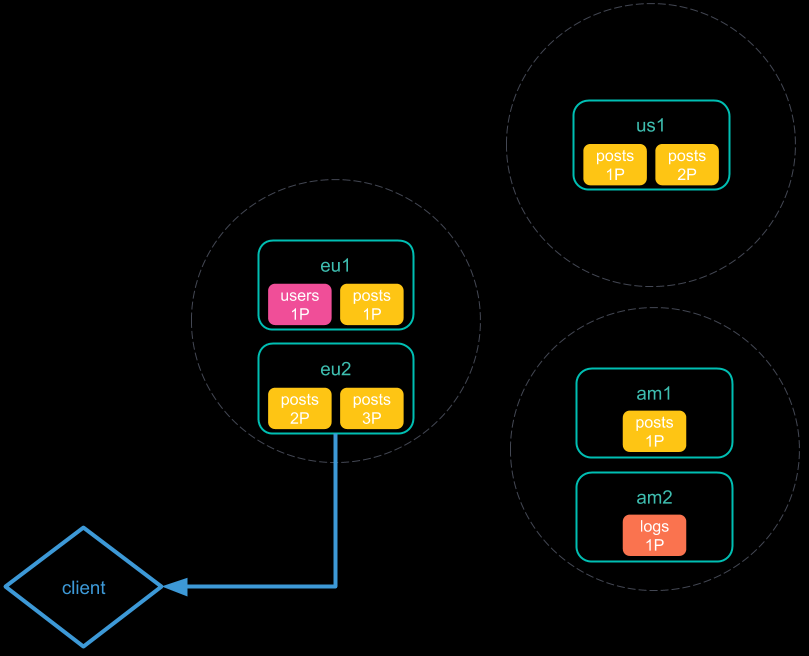
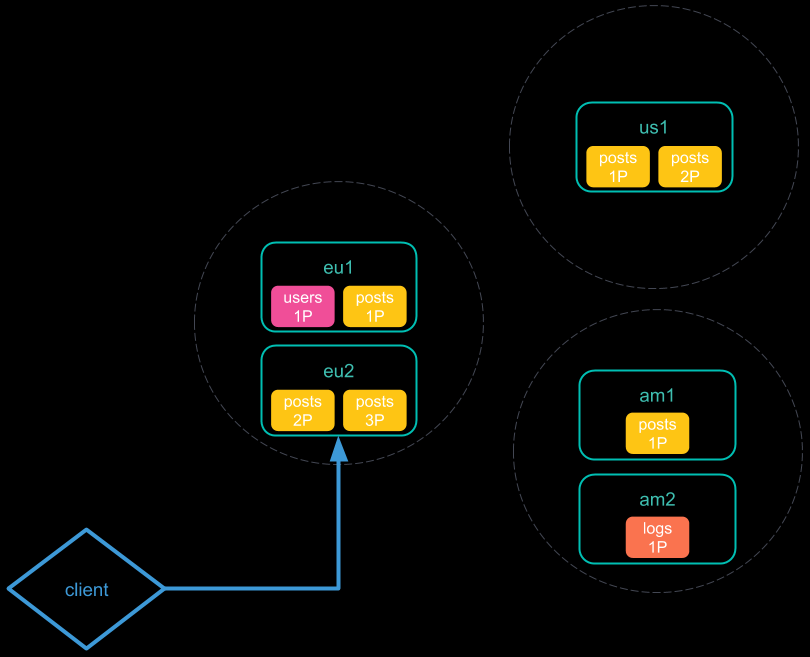
Don’t minimize network roundtrips 检索的步骤:
- 将跨集群搜索请求发送到本地集群。该集群中的协调节点接收并解析该请求;
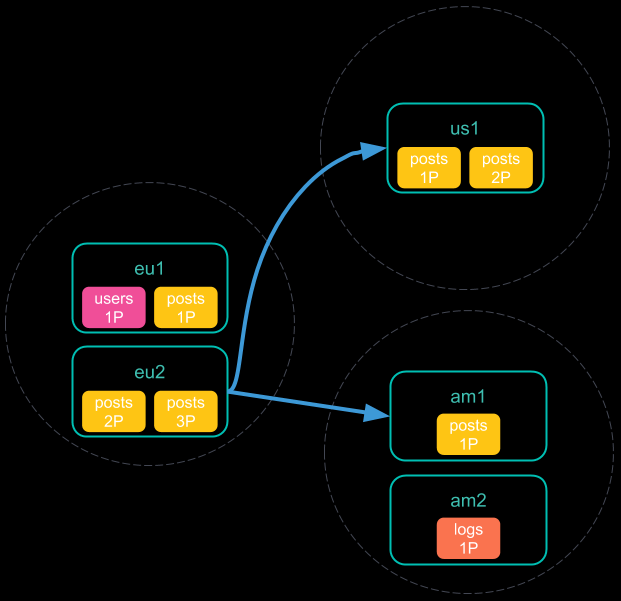
- 协调节点向每个集群发送单个搜索请求,包括其自身的搜索请求。每个集群独立执行搜索请求;
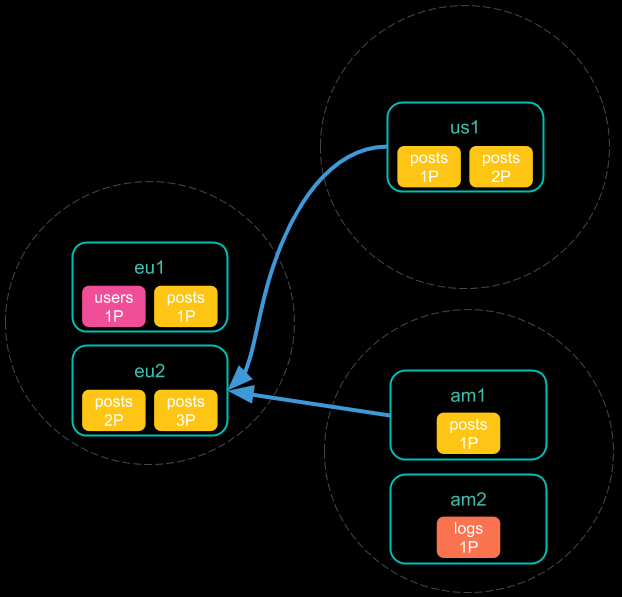
- 每个远程集群将其响应发送回协调节点。该响应中包含了将要执行跨集群搜索请求的分片和索引的信息。
- 协调节点向每个分片(包括其自己的集群中的分片)发送搜索请求。每个分片独立执行搜索请求。
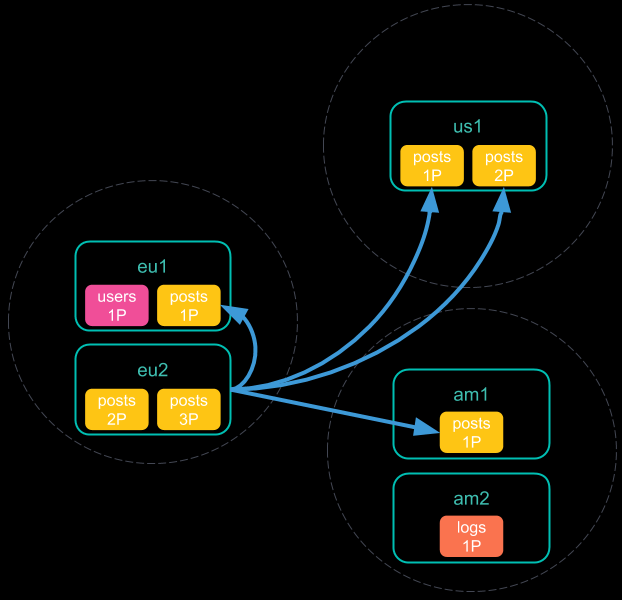
- 每个分片将其搜索结果发送回协调节点。
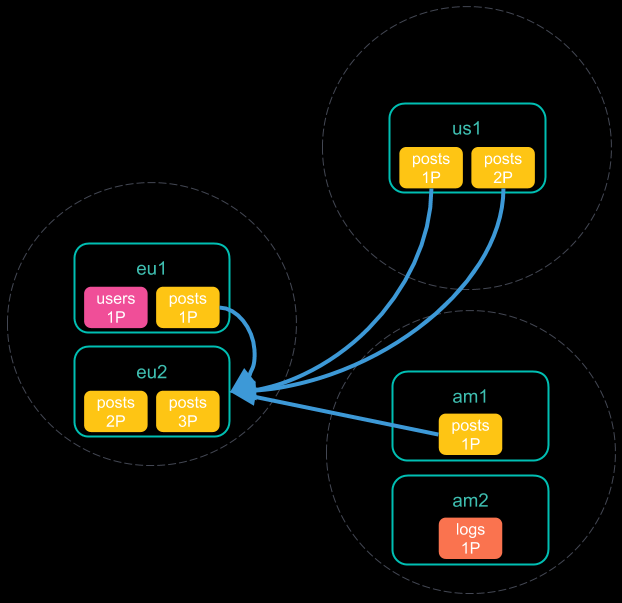
- 从每个集群收集结果之后,协调节点将在跨群集搜索响应中返回最终结果。
4. index_level shard allocation
设置节点属性
1 | // yml 配置 |
配置索引策略:
1 | // 声明多个则表示需要同时满足 |
index.routing.allocation.include.{attribute},节点至少需要满足include中的一个属性;index.routing.allocation.require.{attribute},节点必须满足require中的所有属性index.routing.allocation.exclude.{attribute},索引不能分配在exclude属性的节点上
attribute 属性值由用户自定义 ,也可以使用 Elasticsearch 内建的以下属性:
_name,通过节点名称匹配节点_host_ip,通过主机IP地址(与主机名关联的IP)匹配节点_publish_ip,通过发布IP地址匹配节点_ip,匹配_host_ip或_publish_ip_host通过主机名匹配节点
限制每个节点上的分片数量
使用该配置会影响物理层面的分配,如果节点数不够,可能会导致部分分片状态为 unAssigned1
2index.routing.allocation.total_shards_per_node
cluster.routing.allocation.total_shards_per_node
5. cluster_level shard allocation
allocation awareness 和 Fore awareness 是针对不同机房、机架环境设置的,例如不希望将主副分片分配到同一个机架,或者同一个地区。避免一处停电,影响所有数据。
第一步:设置节点属性,与index_level是相同的,可自定义
1 | node.attr.rack_id: rack1 |
第二步:设置集群层面的分片分配策略,属性保持相同
如下的例子中
awareness.attribute指明了分片分配的感知策略基于rack_idforce.rack_id.values指明了分片分配的范围,主副分片必须在两个机架上。1
2
3
4
5
6
7PUT _cluster/setting
{
"persistent":{
"cluster.routing.allocation.awareness.attribute": "rack_id",
"cluster.routing.allocation.awareness.force.rack_id.values": "rack1,rack2"
}
}
测试
如果只有一个机架属性,副本分配将表现为 unassigned 状态1
2
3
4
5
6
7PUT test_004
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
}
}
6. ingest pipeline
6.1 增删改查
1 | //重复调用,会自动更新原有的声明 |
6.2 condition 语法(可以使用正则判断)
根据数据内容判断1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27// if 案例
PUT _ingest/pipeline/drop_guests_network
{
"processors": [
{
"drop": {
"if": "ctx.network_name == 'Guest'"
}
}
]
}
// 展开对象,多条件判断案例
PUT _ingest/pipeline/drop_guests_network
{
"processors": [
{
"dot_expander": {
"field": "network.name"
}
},
{
"drop": {
"if": "ctx.network?.name != null && ctx.network.name.contains('Guest')"
}
}
]
}
使用复杂的代码语法判断1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// 有些类似于 `script` 操作了
PUT _ingest/pipeline/not_prod_dropper
{
"processors": [
{
"drop": {
"if": """
Collection tags = ctx.tags;
if(tags != null){
for (String tag : tags) {
if (tag.toLowerCase().contains('prod')) {
return false;
}
}
}
return true;
"""
}
}
]
}
按条件使用 processor1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24PUT _ingest/pipeline/logs_pipeline
{
"description": "A pipeline of pipelines for log files",
"version": 1,
"processors": [
{
"pipeline": {
"if": "ctx.service?.name == 'apache_httpd'",
"name": "httpd_pipeline"
}
},
{
"pipeline": {
"if": "ctx.service?.name == 'syslog'",
"name": "syslog_pipeline"
}
},
{
"fail": {
"message": "This pipeline requires service.name to be either `syslog` or `apache_httpd`"
}
}
]
}
6.3 处理器 processors
append,向数组中添加元素,如果数组不存在,则使用给定元素新建。bytes,单位转换,1kb --> 1024convert,类型转换,字符串转数字,或者转booleandate,日期格式化,处理后的字段默认为@timestamp,通过target_field变更date_index_name,按照日期将数据分配到不同索引,使用set处理器修改_index也可以实现类似效果dissect,也称解剖…从单个文本字段中提取结构化字段,与grok类似,但不使用正则表达,所以某些情况下速度比grok更快dot_expander,展开类似fullname.firstname的字段为object格式.drop,移除文档,可以按if条件来dropfail,抛出异常的处理器,用于提示请求出错foreach,遍历数组字段,可以在内部使用所有其他的处理器。grokgsub,将字符串按照pattern进行替换,如果不是字符串类型则会报错。html_strip,去除html标签json,将json字符串转换为对象kv,通过field_split切分为数组,再根据value_split切分key和valuelowercase/uppercase,大小写转换pipeline,类似于include的感觉,引用另一个pipeline的所有处理器remove,移除一个已有的字段,如果字段不存在,抛出错误rename,字段重命名script,脚本处理器set,为字段设值split,分割sort,排序trim,去空格urldecode,解析url中的转义字符,例如%23对应#
一个较为全面的应用案例:
1 | POST _ingest/pipeline/_simulate |
7. x-pack:role、https 配置
7.1 身份认证与用户鉴权
Authentication 认证体系
- 提供用户名、密码
- 提供密钥或
kerberos票据Realms:X-pack中的认证服务
- 内置
Realms(免费),File/Native用户名/密码保存在Elasticsearch中; - 外部
Realms(收费),LDAP/Active Directory/PKI/SAML/Kerberos。
RBAC 用户鉴权
什么是 RBAC: Role Based Access Control(基于角色的权限控制),定义一个角色,并分配一组权限。权限包括索引级,字段级,集群级的不同的操作。然后通过将角色分配给用户,使得用户拥有这些权限。
ES
- User
- Role
- Permission
- Previlege
7.2 集群安全通信: tranposrt + https
配置xpack
- 切换到
es启动用户,修改配置文件xpack.security.enabled: true - 执行
bin/elasticsearch-certutil ca生成ca文件,一路回车默认即可,7.2版本的默认文件名为elastic-stack-ca.p12,存放在安装根目录下 - 执行
bin/elasticsearch-certutil cert --ca elastic-stack-ca.p12生成证书。默认文件名为elastic-certificates.p12,存放在安装根目录下 - 执行
mv elastic-certificates.p12 config/cert/将证书移动到config/cert/目录下 - 将证书拷贝到集群其它节点的
config/cert/目录下 - 修改最终的配置文件为如下所示
1 | xpack.security.enabled: true |
配置用户名、密码
执行 bin/elasticsearch-setup-passwords interactive 初始化各用户的密码
kibana 访问设置
kibana 使用 https 时还需要修改如下三个参数:
1 | elasticsearch.hosts: ["http://localhost:9200"] |
生成 pem 文件需要使用到 openssl,执行如下指令:
1 | openssl pkcs12 -in elastic-certificates.p12 -cacerts -nokeys -out elastic-ca.pem |
kibana的https设置
- 执行
bin/elasticsearch-certutil ca --pem,生成的elastic-stack-ca.zip文件中包含了ca.crt,ca.key两个文件; - 解压缩后,将两个文件拷贝到
config/cert目录下,编辑kibana.yml文件的如下配置;
1 | server.ssl.enabled: true |
由于证书是自签的,仅能用于测试,所以kibana中会有SSL相关的报错
あなたがいきる、この世界に
