1.消息队列的应用场景:
- 解耦:将不同的系统之间解耦开来,比如说我有一个上游的订单系统,订单完成之后,我需要操作
A库存系统、B用户系统 来进行扣库存、增加会员积分等等操作。现在A,B子系统都需要来对接我的执行结果。不解耦的话,需要在订单的代码里编码来执行。如果A,B发生需求变更的话就会改动订单系统的代码。而使用消息队列之后,就不需要关心下游系统的具体逻辑了,由A,B自行通过订阅的方式来进行逻辑处理。 - 异步:(事件驱动)同步执行流程时间长,或者说用户并不关心邮件发送成不成功,只要购买成功就可以了。
- 削峰(限流):这个只有在大并发场景才会用到,如果我的请求非常多,那么我可能会把请求先放到消息队列中,去排一下队,避免把应用直接压垮。这里其实会牵扯到有关联性其它问题,比如说:
- 如何设计一个秒杀系统
ELK架构中为什么不直接从logstash —> Elasticsearch而是要Logstash —> Kafka —> Elasticsearch
消息队列总览图
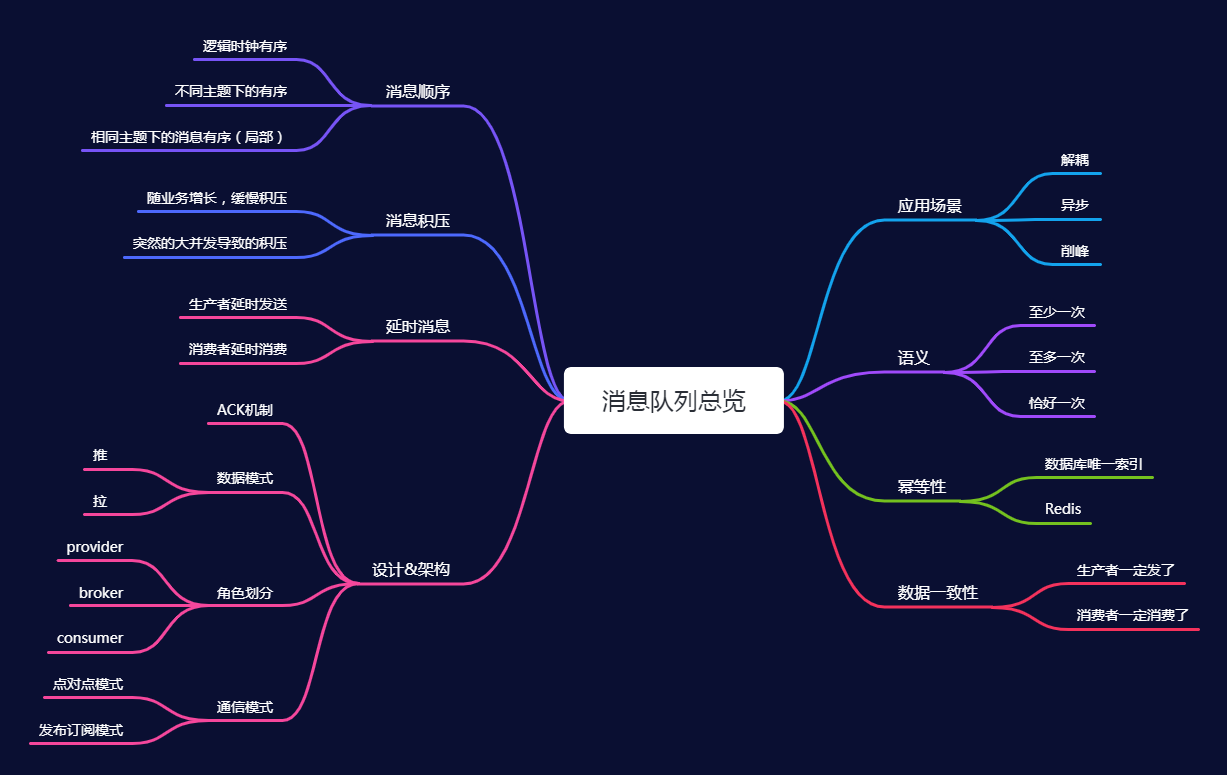
##
2.消息队列重难点:
如何保证生产者只发送一次
这个问题其实很难做到,或者说没办法做到,在分析问题前可以拆解为两个小问题:
- 如何保证消息一定发出去了?
- 如何保证只发了一次?
对于第一点,可以使用重试或者使用分布式事务(分布式事务本身又是一个大坑),重试超过一定次数,需要考虑人手工介入。
对于第二点,通常是不限制生产者的发送次数,在消费端通过幂等来解决。
如何保证消费者一定消费成功
重试 + ACK 机制,消费成功后,发送 ACK 进行确认。
数据一致性
- 至多一次,消息至多只消费一次,有可能没有消费成功,适用于日志类型的数据允许丢失的场景
- 至少一次,消息最少也会消费一次,存在重复消费的可能,需根据业务情况考虑,是否需要做幂等操作
恰好一次,最严苛的语义,不多不少执行一次。这个其实挺难保证的,需要业务来进行辅助解决
超时、重试、幂等
通常情况下的应用中,80%+ 的消息数据都会是恰好发送一次,恰好也被消费一次的状态。
重复消费的场景:
从生产者到消息中间件之间,生产者可能重复发送。例如生产者发送过程中出现超时,因此生产者不确定自己是否发出去了,重试
消息中间件到消费者,也可能超时。即消息中间件不知道消费者消费消息了没有,那么重试就会引起重复消费,这里又分为两种子情况:
- 消息传输到消费者的时候超时
- 消费后,进行
ACK确认时超时
而解决重复消费问题的方案就是保证幂等。(当然有些场景下的数据重复消费并不会造成影响,可以不用处理)
3.如何解决幂等
- 根据消息内容的业务特征去重,例如根据
id去重。- 去重方式可以选择数据库唯一索引或者
Redis,这种方案属于先检查数据库是否唯一索引冲突,或者Redis是否存在某个key(check +do something) - 延伸问题:如果使用
check + dosomething会有几率出现并发问题。检查之前没有,检查之后出现了该key值。
- 去重方式可以选择数据库唯一索引或者
4.消息顺序问题
通常来说,用了 mq 就不太会要求顺序,或者说只会要求局部有序
- 从本质上来说,队列本身就是有序的,消息的顺序需要生产者、消费者互相来保证,中间件并没有所谓的重排序机制。
- 生产者需要控制逻辑,A 成功之后才能发送 B
- 消费者则不相同,一般来说,
mq中有一个offset机制,如果我消费失败了,我不发送ack确认的话,是不会消费下一条消息的 - 而对于中间件本身来说,由于一个
topic或者说queue会分为多个partition分区,中间件只能保证某个分区的顺序,想要做到严格的顺序要求其实不适合使用中间件!!!!!。做同步处理他不香吗。
5.消息积压问题
本质问题:生产者和消费者的效率不一致,消费者效率太慢,解决方法可以从两个方面来考虑:
- 限制生产者速率(一般不会)
- 提高消费者的效率
- 提高单条消费的效率
- 增加消费者数量
- 使用线程池来消费
partition,消费者组Group,
除此之外,积压其实还得考虑是突然的积压(偶发,增加集群规模,先把东西保存下来,慢慢的都会消费完),还是业务增长而缓慢导致的不断积压(增加消费规模,说明容量预估就不正确,)
6.如何实现延时消息
- 中间件是否支持延时
- (生产方投递到延时队列里)然后通过定时任务扫描,时间一到,定时发送
- 先发送到一个特殊队列,消费者先存储下来。等待一段时间,然后发送到真正的主题中。
- 业务方程序控制
- 消费者程序控制
7.数据推送模式:
- 推:服务端主动推,服务端压力大
- 拉:客户端主动拉,不够实时
8.消息队列的缺点(反直觉问题)
- 增加了系统复杂性
- 可用性降低
- 一致性难保证
- 升华主题:所有的中间件引入都会引入类似的问题
9.如何选择消息队列
trade off问题 ,需要看业务场景来考虑看技术积累深度,团队内部的人员掌握程度如何
看维护难度、看社区成熟度。是否容易找到问题