1. 位图与布隆过滤器
位图通常用于状态检索,通过与或操作来判断,检索效率为 O(1)。相比数组而言,虽然检索效率相同,但可以减小内存占用,一个 2^32=40亿 的位图占用为 512M,同样的情况下数组在使用 boolean 类型时内存占用为位图的 8 倍,而使用 int32 时占用为 4 字节,内存占用是位图的 32 倍;
由于位图所使用的单元已经是最小的单位 bit,为了再次缩小位图空间,想到的办法是压缩数据(Hash之后再存储),缩小元素个数。但是压缩数据势必会引起 Hash 冲突,压缩的越小,冲突越大。于是又回到了 Hash 冲突解决法: 开放寻址、链式 Hash ;
链式 Hash 无法减小空间(why?),而开放寻址有一种优化策略:“双散列”。其原理是使用多个 Hash 函数分别求 Hash 值,得到多个下标,将对应的下标位置均置为 1 ,而这其实就是 “布隆过滤器” 的设计思想,通过多个下标来判断,就减小了 Hash 冲突,当然也带来一个问题 —> 布隆过滤器的删除,需要通过计数器,或者定时重建才行,不能直接将对应位置置为 0;
同样的,“布隆过滤器” 也有自己的缺点:即使任何两个元素的哈希值不冲突,而且我们查询对象的 k 个位置的值都是 1,查询结果为存在,这个结果也可能是错误的。这也称为是布隆过滤器的错误率(通常来说,误判可以当成实际存在来处理,大部分情况是不影响业务的。例如用户注册时,需要检测用户名是否已存在,已存在的话需要更换用户名重新注册)
布隆过滤器图示:
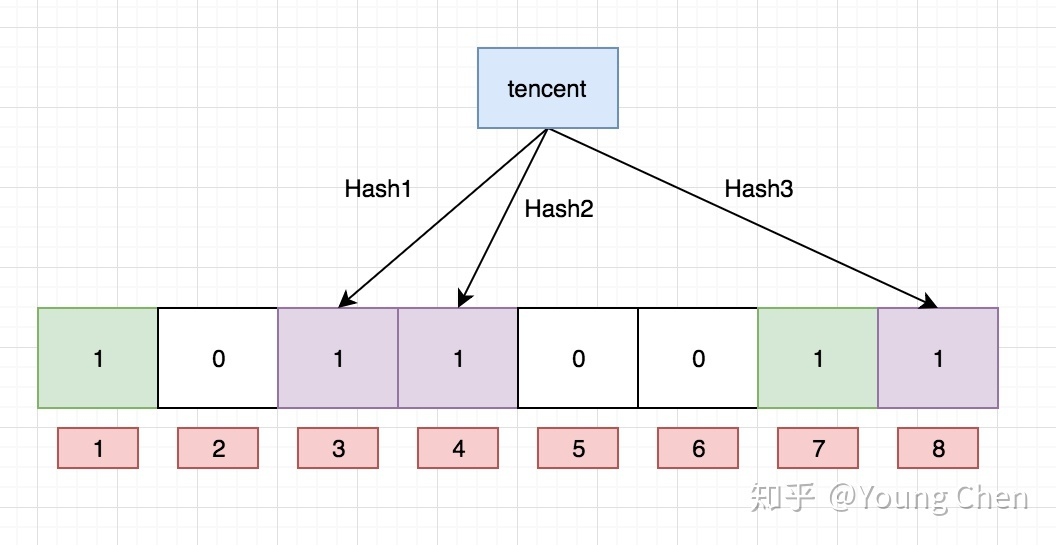
位图是只有一个特殊的哈希函数,且没有被压缩长度的布隆过滤器。
2. 倒排索引
与倒排索引概念相对应的概念称为正排索引,也就是我们常规的数据库存储方式,以 id 对应一整行数据。当我们给定一个 id 时可以很快地找到该列,但如果给定的是某个字段中的词,正排索引只能一行一行到遍历,使用 Like 查找。当文档数据特别多,字段也特别多的时候,正排索引的查找效率就不行了,于是就有了倒排索引。根据关键字创建对应的文档索引,查找时直接根据关键词定位到数据本身。
倒排索引中的关键字 (key)的集合也称为 字典(Dictionary),而 key 后面对应的文档集合也称为记录列表(posting_list),倒排索引常见于各种全文检索场景中。
2.1 倒排索引的创建
倒排索引的创建步骤大致如下:
- 给每个文档进行唯一编号,对数据进行排序(
why?),然后开始遍历文档;
- 给每个文档进行唯一编号,对数据进行排序(
- 解析每个文档中的关键字,按照 < 关键字,id,关键字位置> 的结构进行存储,存储关键词位置的原因主要是组合查询时,通常需要判断多个关键词的位置是否足够接近来获取相关性算分(< 关键字,id,关键字位置>只是最基础的信息,为了加快检索速度,通常存储的内容更多);
- 将关键字作为
key存入Hash表,如果posting_list已经存在则在后面追加文档,否则,新建一个posting_list;
- 将关键字作为
- 重复
2、3的步骤,处理完所有文档,完成倒排索引的创建,最后的数据存储结构图可以参考如下图例:
- 重复

2.2 倒排索引的查询
如果只是查询单个关键字在哪些文档中出现,直接以查询的关键字作为 key,得到的 posting_list 就是需要的结果了,但是如果需要查询同时包含关键词A,以及关键词 B 的文档时,就需要想办法获取两个 posting_list 中的公共元素。
假设 posting_list A,B 都是没有排序的链表,那么在寻找公共元素时,必须挨个比对 A ,B 两个链表中的每一个元素,这样查找的复杂度为 O(m*n),如果是排好序的链表,那查找速度就变为 O(m+n) 了
归并的执行过程为,通过指针 p1,p2 分别指向链表 A,B 的第一个元素,比对是否相等,此时有以下三种情况:
- 如果相等则直接放入结果集,
p1和p2分别向后移动; - 如果
p1 > p2,那么将p2指针向后移动,p1保持位置不变; - 如果
p1 < p2,那么将p1指针向后移动,p2保持位置不变;
重复该步骤,直到 p1 或 p2 到达链表尾部。
3. 利用跳表加速倒排
使用跳表存储 posting_list 时,可以按照如下方式判断:
如果 A 中的当前元素小于 B 中的当前元素,我们就以 B 中的当前元素为 key,在 A 中快速往前跳;如果 B 中的当前元素小于 A 中的当前元素,我们就以 A 中的当前元素为 key,在 B 中快速往前跳。如此一来,中间的很多元素就可以忽略掉,进一步提升了查找速度。
跳表结构图示:
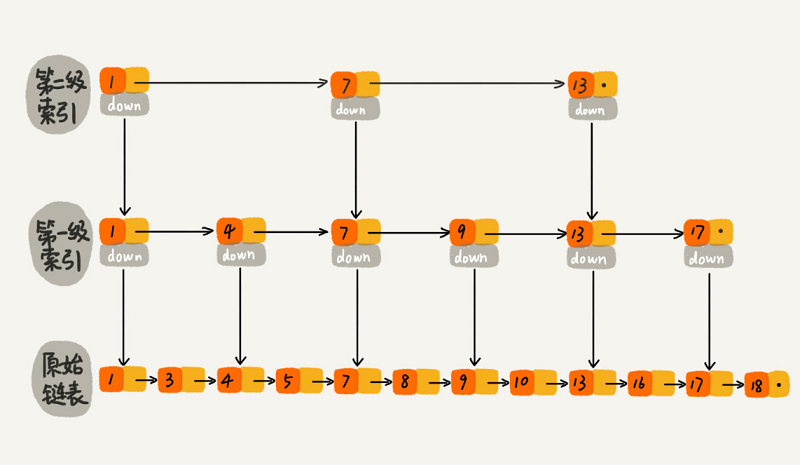
常见的开源检索框架大多都使用到了这种方式。
4. 利用 Hash、位图加速倒排
回到起点再试想一下。查找 A , B 中的公共元素,其实就是判断 A 是否在 B 中存在,hash 加速适用于求交集时,一个集合特别大(A),另一个相对比较小(B)
那么我们可以提前将 A 中的元素映射为 Hash 表,然后对 B 中的原始逐个进行 Hash 查找即可,但前提是必须提前分析好,需要把哪些 posting_list 映射为 Hash 表,需要进行映射的数据不能进行频繁变动,不然就没有意义了,同时原始的 posting_list 也必须保留,不然就取不到原始数据了。
位图是特殊的 Hash 结构,所以也是同样的道理。但适应场景有所不同:使用位图时,需要把所有的 posting_list 都转为位图,然后通过位运算来判断,同时具有以下局限性:
- 位图法仅适用于只存储
ID的简单的posting list。如果posting list中需要存储复杂的对象,就不适合用位图来表示posting list了。 - 位图法仅适用于
posting list中元素稠密的场景。对于posting list中元素稀疏的场景,使用位图的运算和存储开销反而会比使用链表更大。 - 虽然位图只需要用
1个bit就能表示元素是否存在,但每个posting list都需要表示完整的对象空间。假设有2^32数量的文档,哪怕一个关键词只对应两个id,申请位图时也需要完整的2^32 bit的空间,只不过对应位置上全是0而已,这个占用高达512M。
成熟的工业界系统中,为了解决位图的空间消耗问题,经常会使用一种压缩位图的技术 Roaring Bitmap 来代替位图,诸如各大数据库、Lucene 等。
5. Roaring Bitmap
Roaring Bitmap 是位图设计的另类思想,它将一个 32 位的整数划分为高 16 位和低 16 位。对于高 16 位,Roaring Bitmap 将它存储在一个 有序数组(变长) 中,每一个数字代表一个 “桶” ,而低 16 位存储的是一个 2^16 的位图,每个 “桶” 都对应着一个位图。
Roaring bitMap 图示:
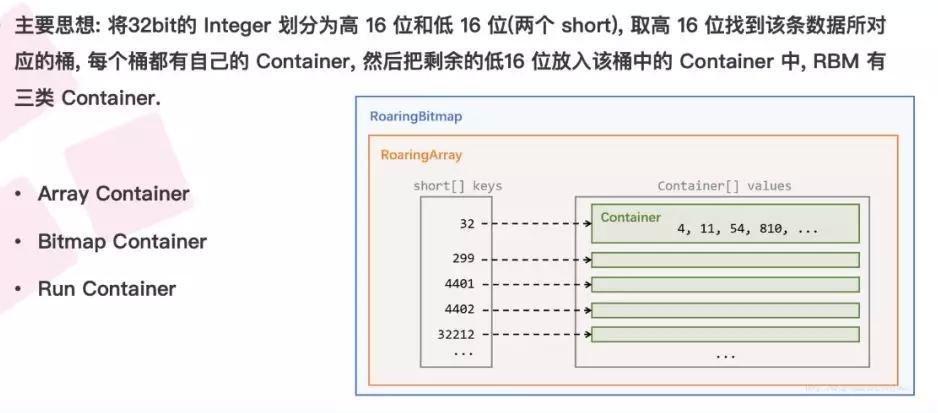
当需要进行查找时,先通过二分查找获取到 “桶” 的位置 O(logn) ,再在位图中进行与或操作 O(1),牺牲些许查找性能的同时,带来的好处是位图空间压缩
还是以一个关键词对应两个 id 为例,使用位图时必须申请全量空间 2^32 bit = 512M ; 而使用 Roaring bitmap时只需要申请两个桶(高位计算结果相同的话只需要一个)4字节(short 类型占两字节),低位的位图占用仅为 2^16=8k
所以Roaring Bitmap的总体思想,其实就是将不存在的桶的位图空间“全部”(并不是)省去这样的方式,来节省存储空间的
提到位图时也说过,当元素稀疏时,使用位图(Bitmap Container)的占用反而会比链表高,Roaring Bitmap 基于这个思想,当低位存储的内容少于 4096 时,使用变长的有序数组(Array Container)来存储,大于 4096 之后才采用位图。
为什么是4096
Roaring Bitmap 使用的是 short 类型的数组,每个元素为 2字节,当元素达到 4096 时,内存占用为 8k,与 2^16 的位图占用相当,所以选择的界限为 4096
roaringbitmap 并不能保证一定压缩空间,极端情况下会恢复为位图
Lucene 的 RoaringDocIdSet 流程图
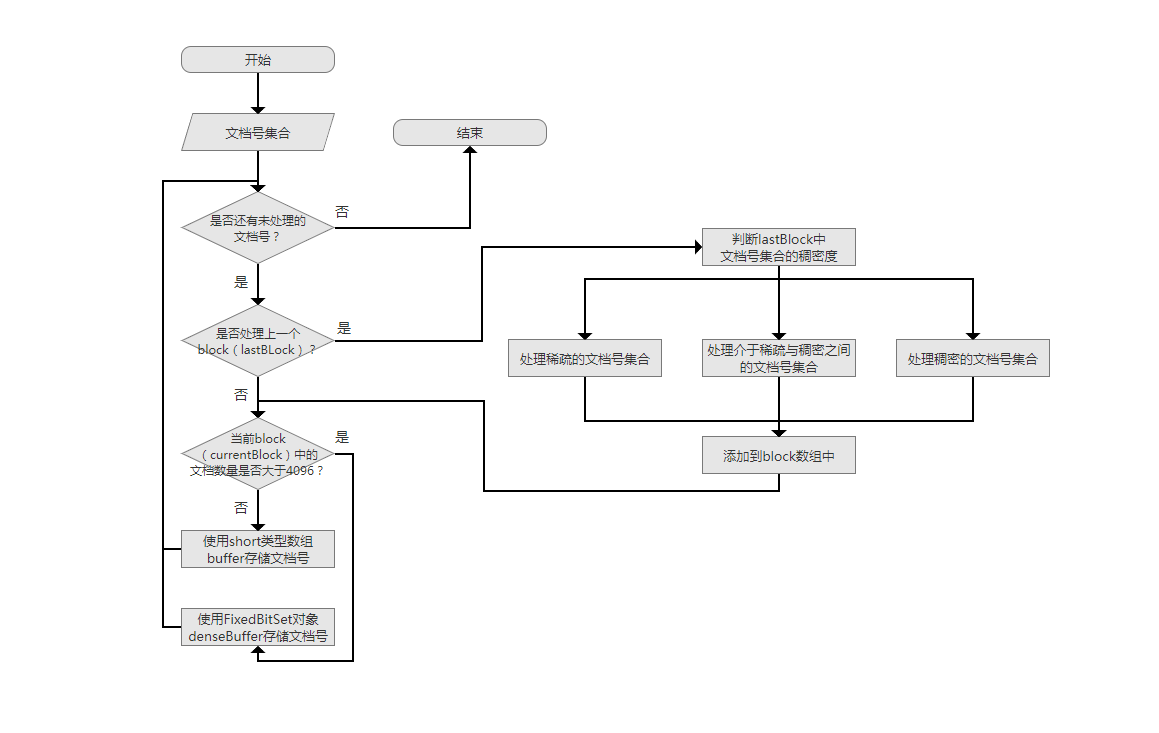
图中的 block 其实就是所谓的 “桶”。
6. 联合查询加速法
6.1 调整次序法,适用于多个 posting_list 集合数量差距较明显的场景
假设通过多个关键词联合查询,得到了三个 posting_list A,B,C;集合中包含的元素数量分别为 2,20,40 并且包含关系为 A < B < C。已知普通链表求交集的复杂度为 O(m+n);同样是求三个集合交集的话
- 先计算
(A ∩ B)得到结果后再∩ C的复杂度为(20+2)=22;得到的交集结果为2, 再计算(40+2)=42,总计64 - 先计算
(B ∩ C)得到结果后再∩ A的复杂度为(40+20)=60;得到的交集结果为20,再计算(20+2)=22,总计82
当然,调整次序法满足交换律,例如: A∩(B∪C)= (A∩B)∪(A∩C)
6.2 快速多路归并
适用于元素数量差距不明显的场景,利用跳表的性质,快速跳过多个元素,加快多路归并的效率;
6.3 预先组合法
例如经常查 A+B+C,那么可以组合 posting_list ,使其对应的 key 为 A+B+C;
6.4 缓存法加速
例如 elasticsearch 中的 filter 的运用
